3. Seminar: Ereignisdaten
Fortgeschrittene quantitative Methoden
Wintersemester 2024-2025
Beispiel: Biographie der Partnerschaft
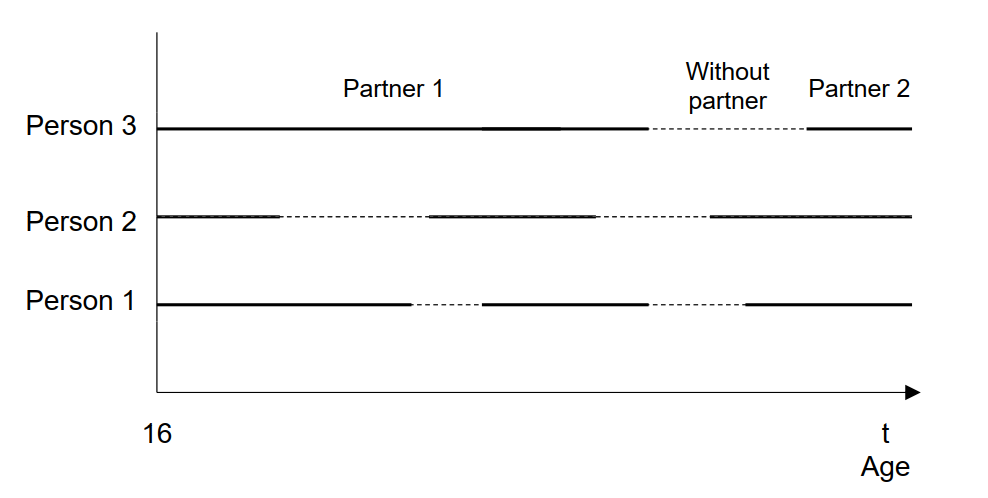
Biographie der Partnerschaft
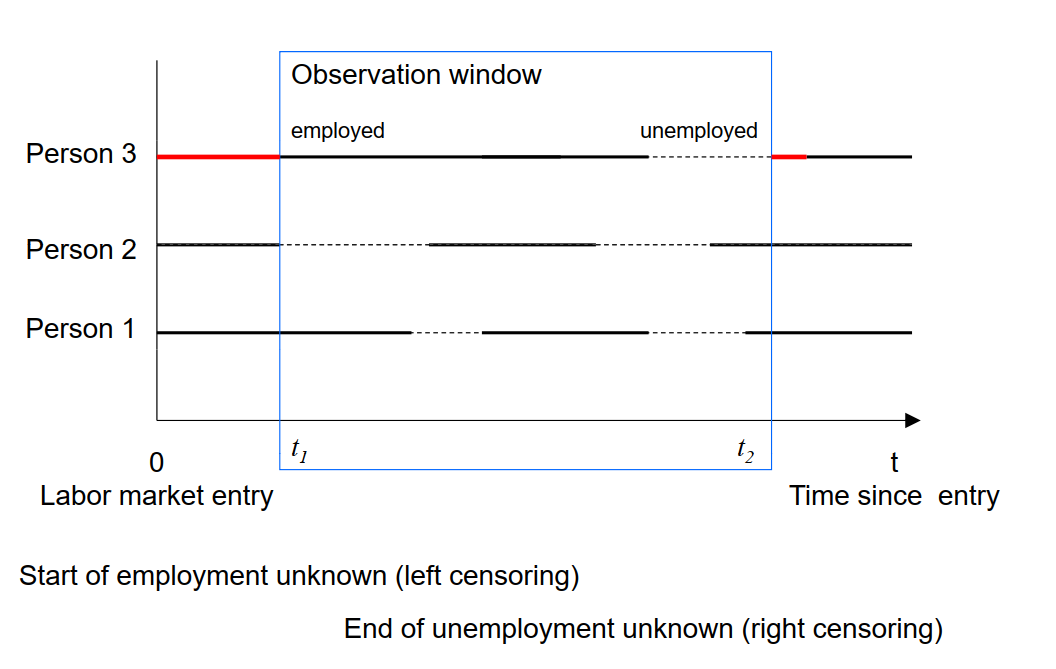
Beispiel: Arbeitslosigkeit
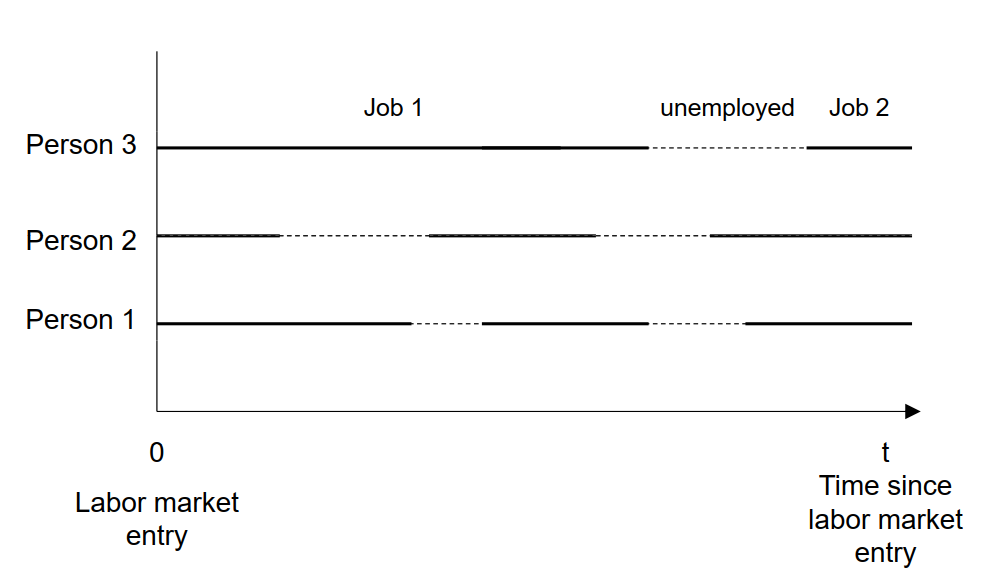
Arbeitslosigkeit
Beispiel: Sterblichkeit einer Geburtskohorte
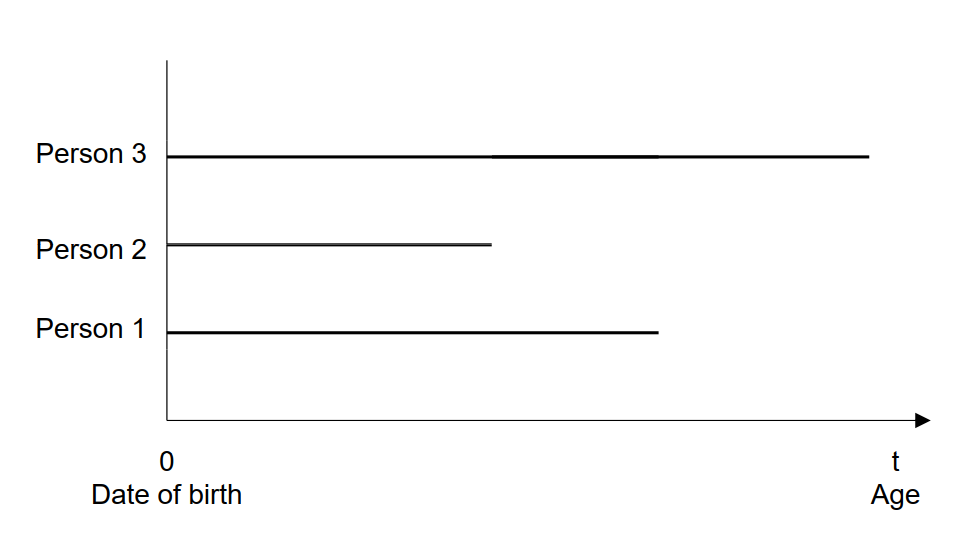
Sterblichkeit einer Geburtskohorte
Beispiele: Überleben von start-up Firmen
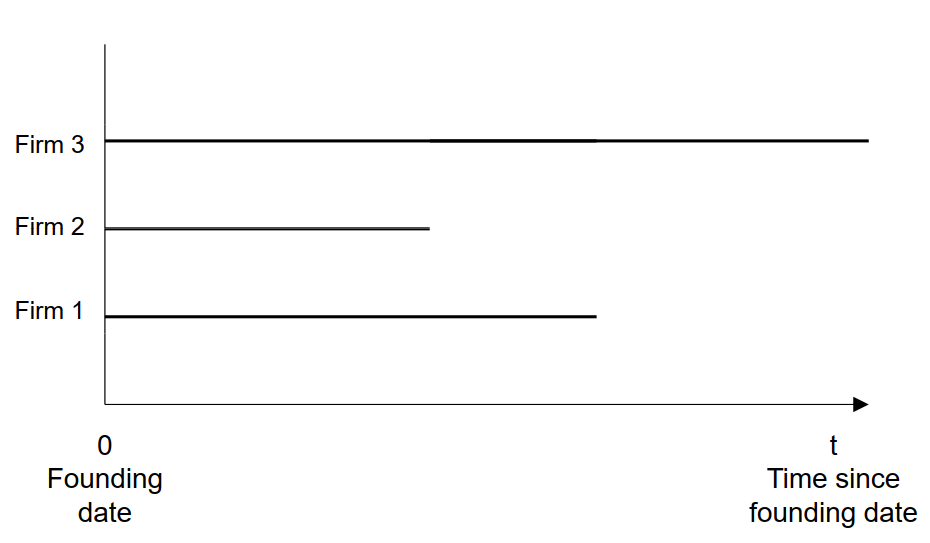
Überleben von neu gegründeten Unternehmen
Grundbegriffe
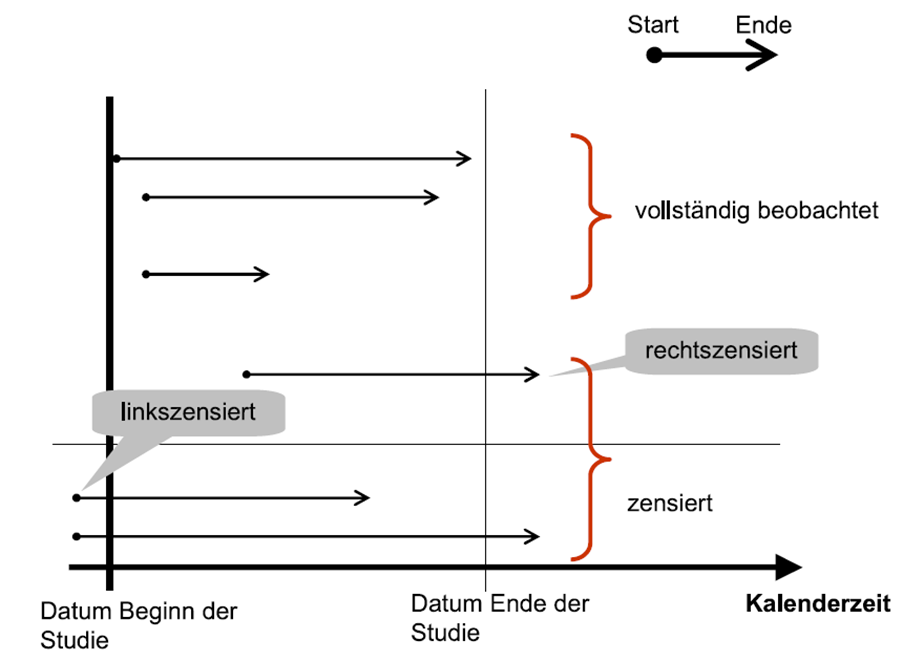
Aus: Windzio, M. (2013). Regressionsmodelle für Zustände und Ereignisse: Eine Einführung. Springer-Verlag, S. 88.
Grundbegriffe
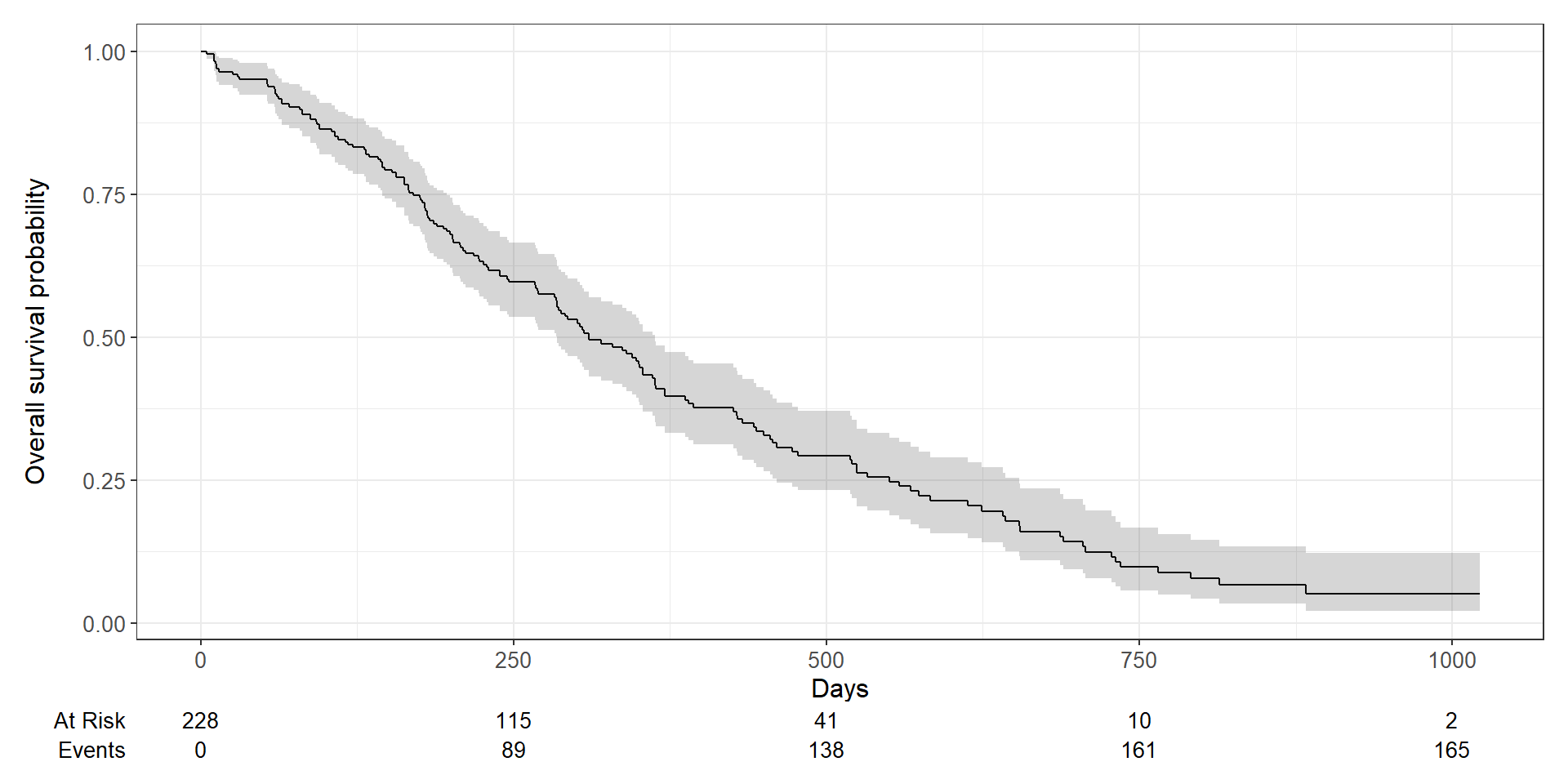
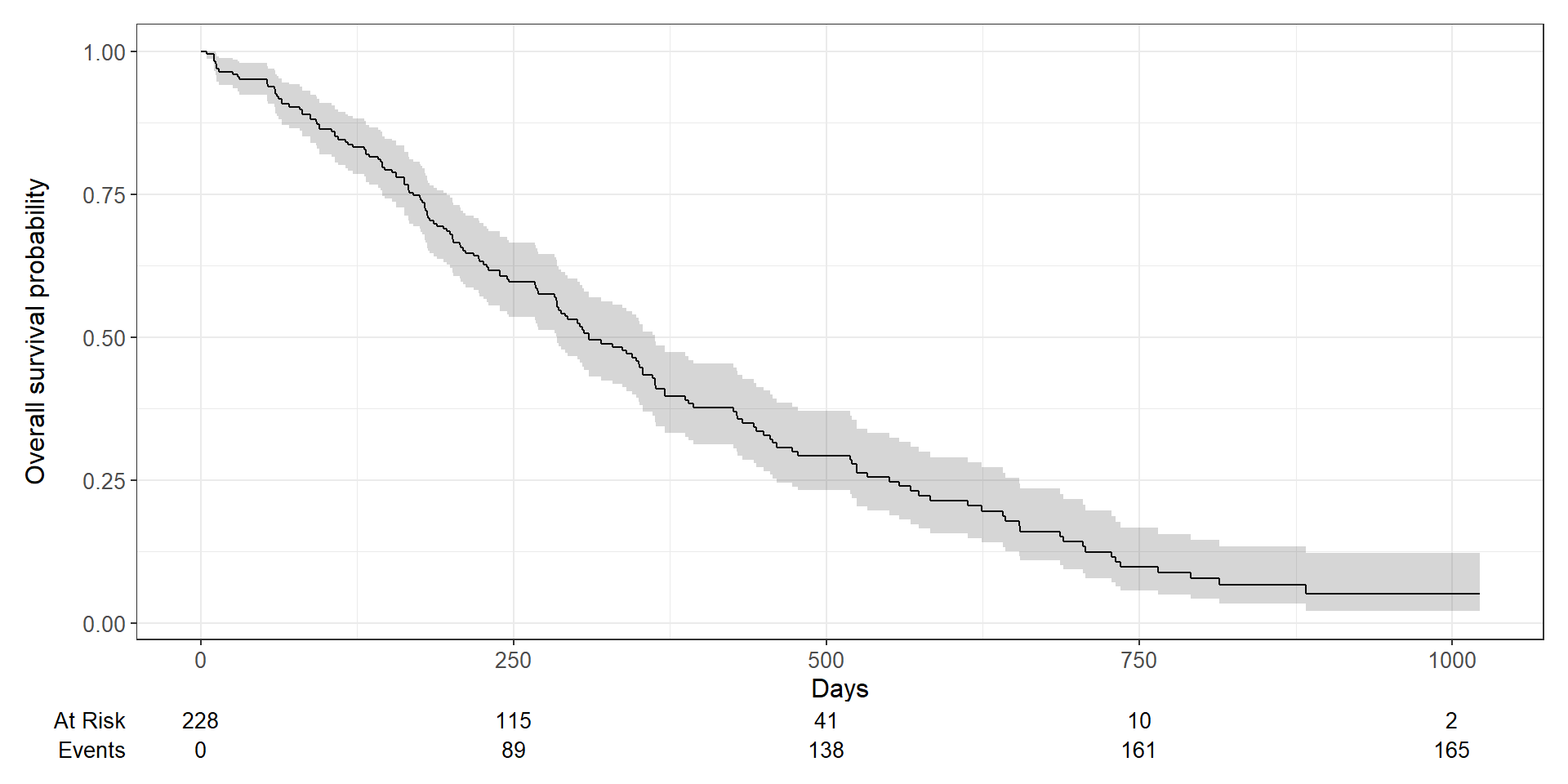
Erstellen von Kaplan-Meier Kurven
Kaplan-Meier-Methode gängigste Methode zur Visualisierung von Überlebenswahrscheinlichkeiten
Erstellen von Kaplan-Meier Kurven nach Karnofsky-Index
Unterscheiden sich PatientInnen mit niedrigem oder hohem Karnofsky-Index?
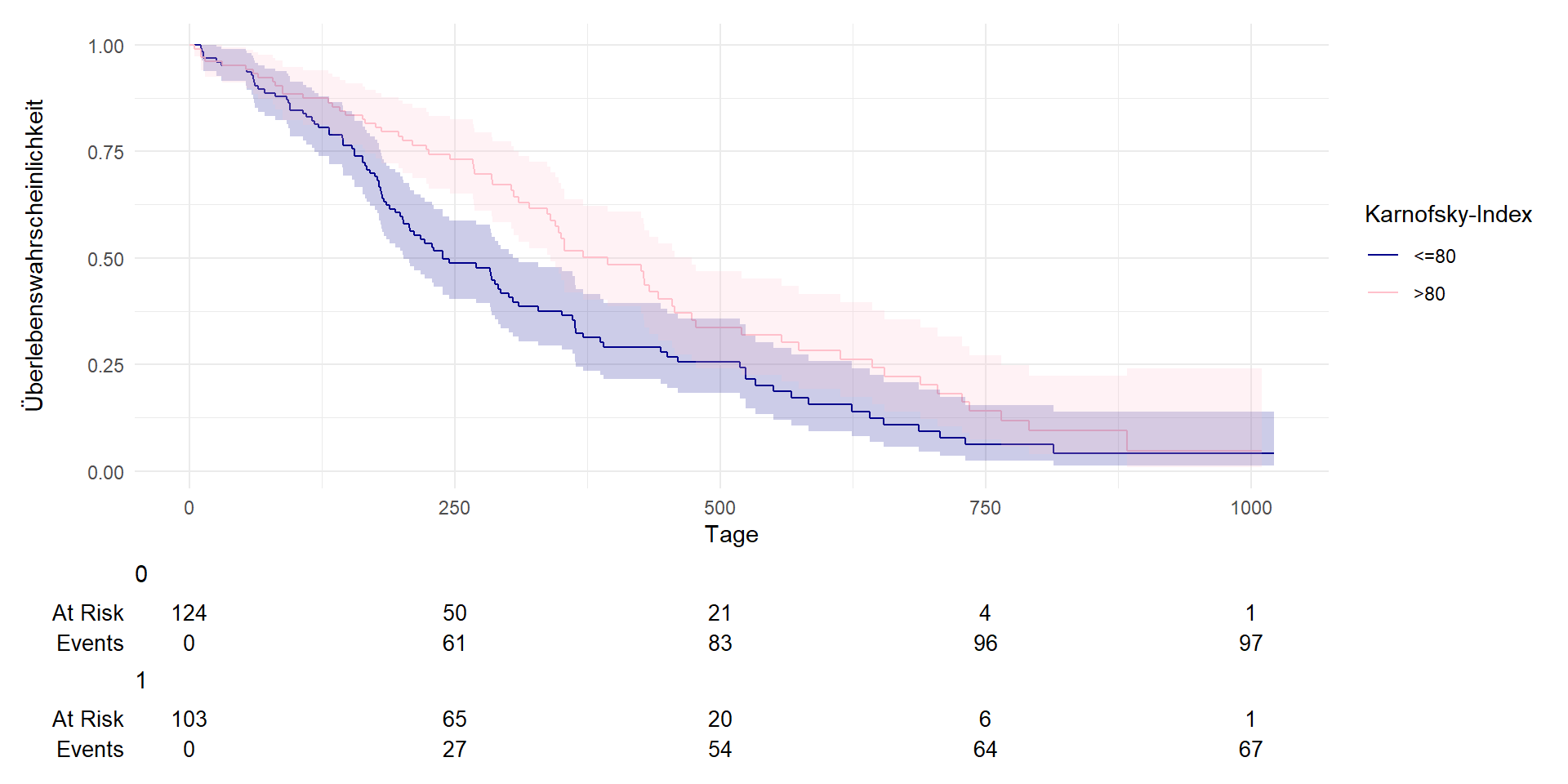
survfit2(Surv(time, dead) ~ karnofsky_hoch, data = df) %>%
ggsurvfit() +
labs(
x = "Tage",
y = "Überlebenswahrscheinlichkeit",
color = "Karnofsky-Index"
)+
add_confidence_interval() +
add_risktable() +
scale_color_manual(values = c('darkblue', 'pink'), labels = c("<=80", ">80") ) +
scale_fill_manual(values = c('darkblue', 'pink'), labels = c("<=80", ">80") ) +
theme_minimal() + guides(fill = "none")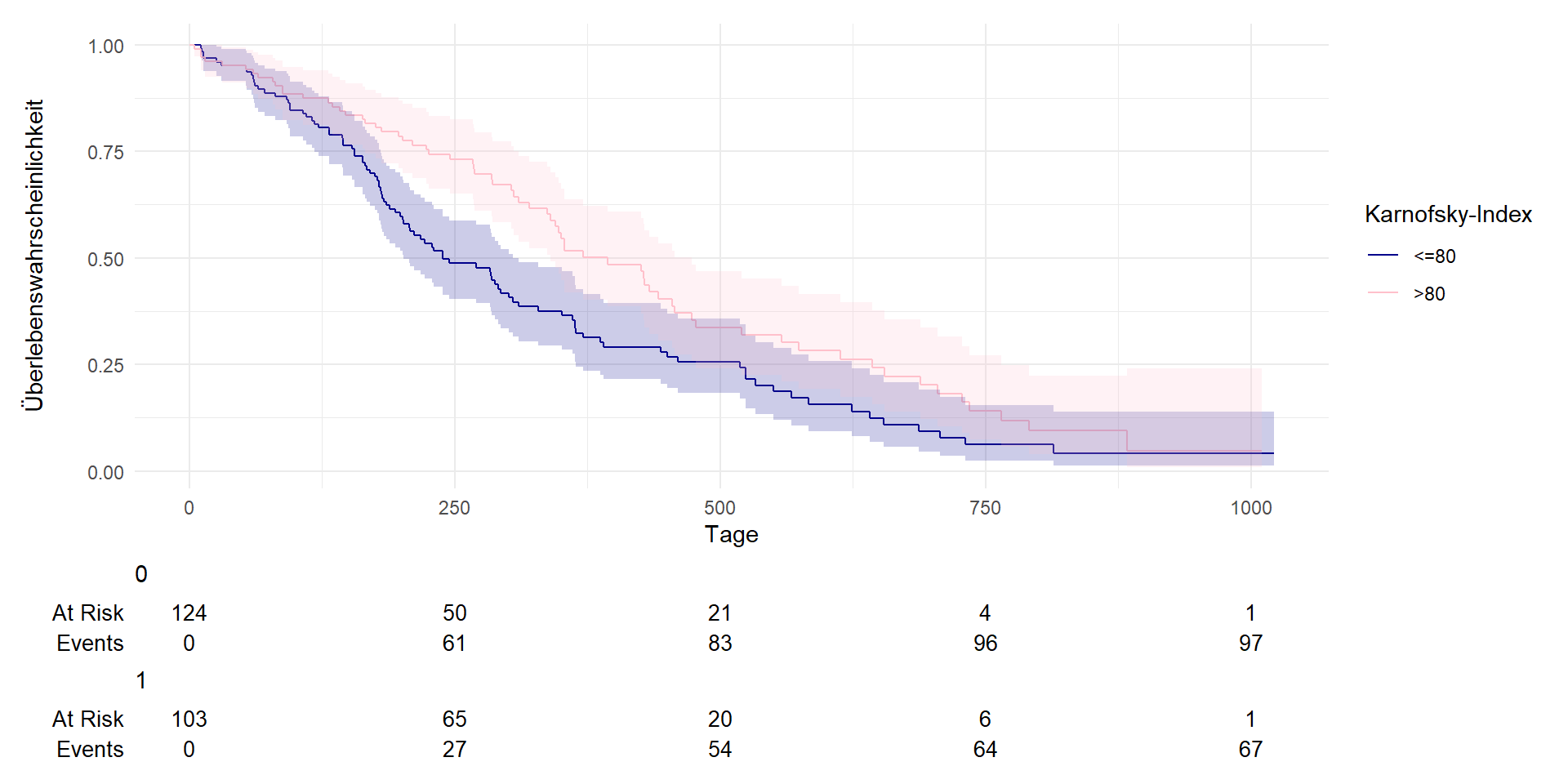
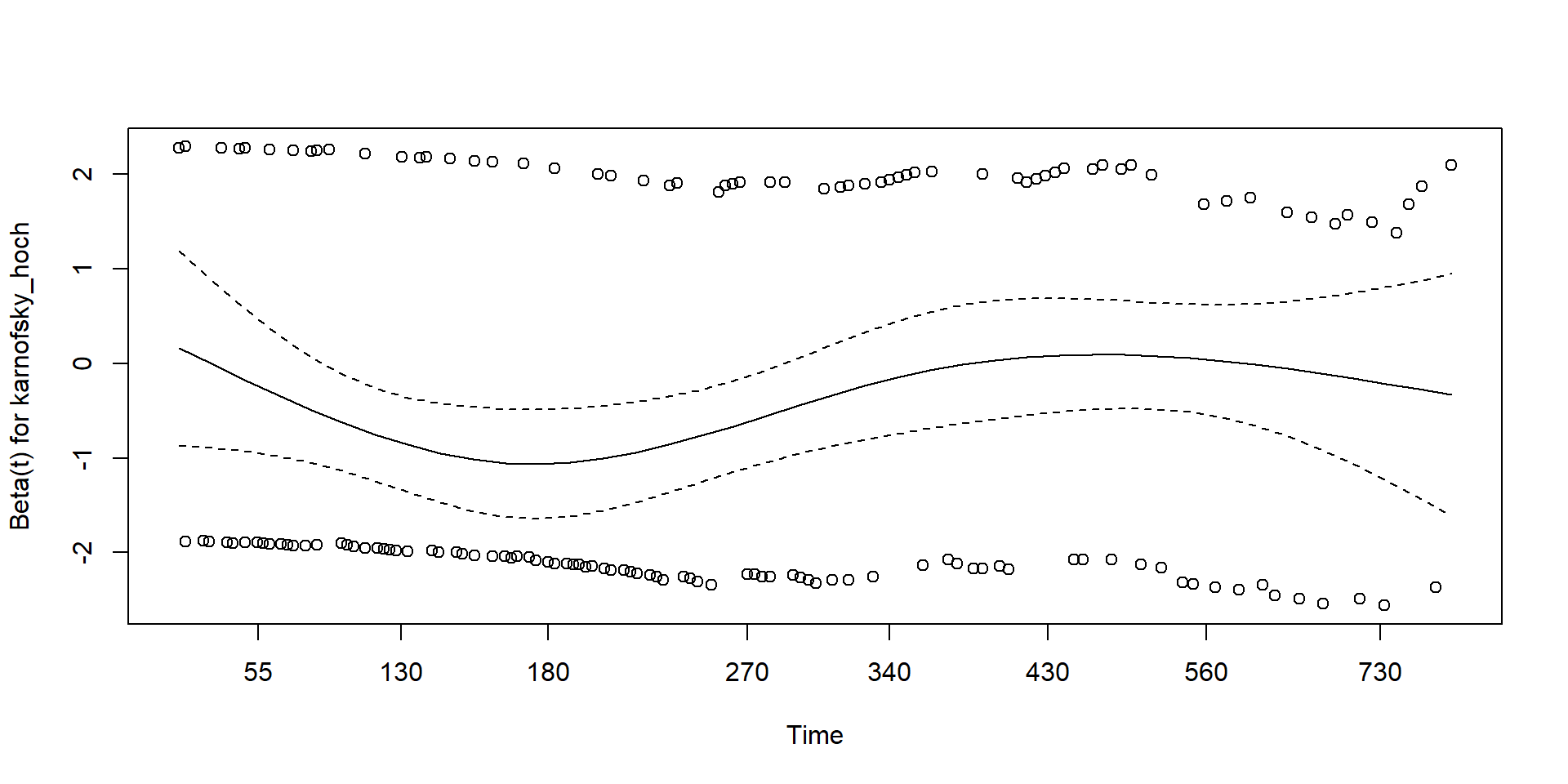
Proportionalitätsannahme
Nun testen wir die Proportionalitätsannahme.
Nullhypothese: Hazard-Raten proportional, also kein Zusammenhang mit der Zeit
model1 = coxph(Surv(time, dead) ~ karnofsky_hoch, data = df)
# Überprüfung der Proportionalitätsannahme
test_proportionality <- cox.zph(model1)
# Ergebnisse anzeigen
print(test_proportionality) chisq df p
karnofsky_hoch 1.59 1 0.21
GLOBAL 1.59 1 0.21