| lz | |||
| Predictors | Estimates | CI | p |
| (Intercept) | 5.40 | 3.83 – 6.96 | <0.001 |
| alter | 0.04 | 0.01 – 0.07 | 0.007 |
| Observations | 34 | ||
| R2 / R2 adjusted | 0.207 / 0.182 | ||
2. Seminar: Paneldaten
Fortgeschrittene quantitative Methoden
Wintersemester 2024-2025
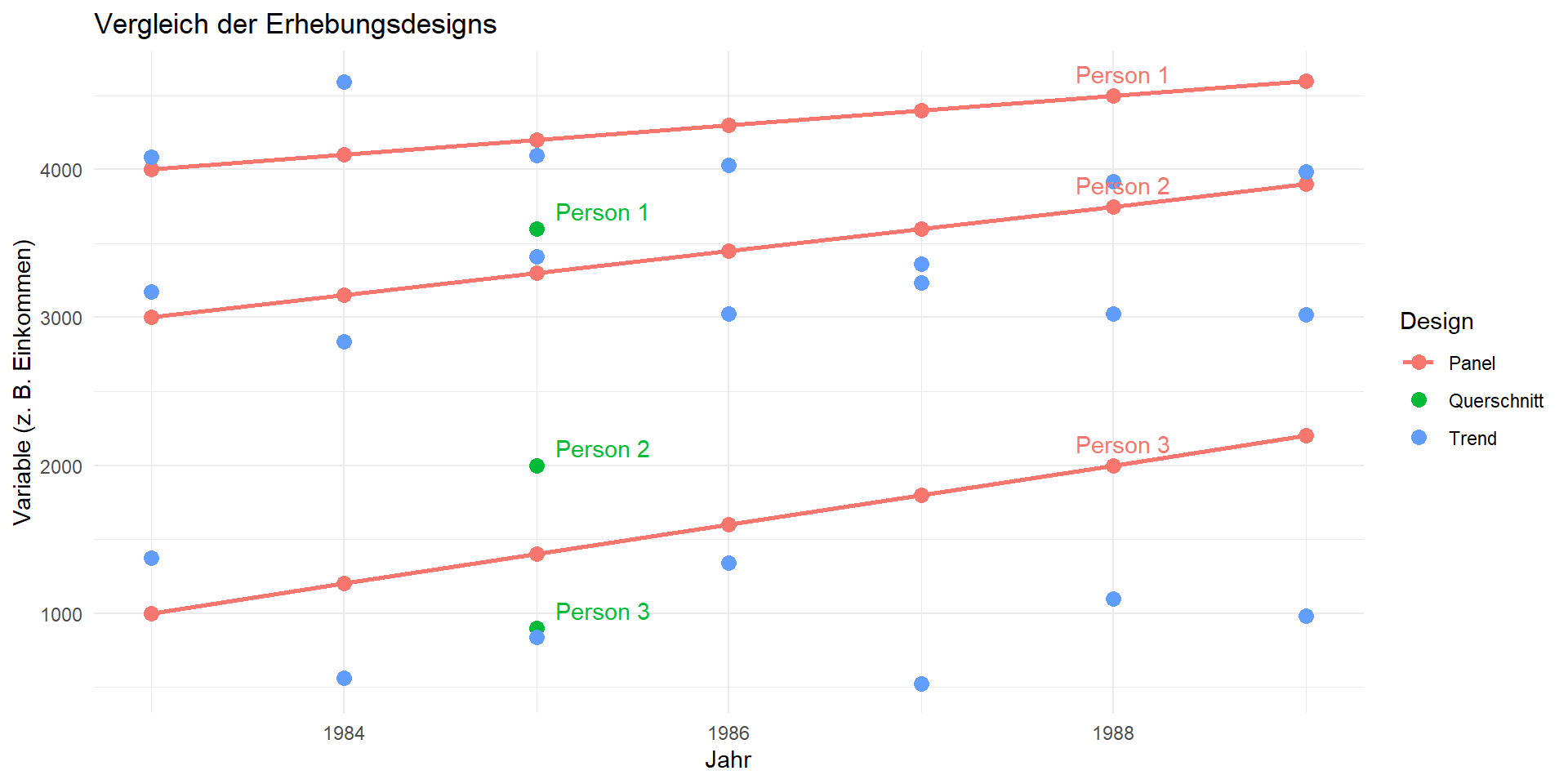
Querschnitt-, Trend- und Paneldaten
Welche Fragestellungen bieten sich bei welchem Studiendesign an?
Fehlerquellen
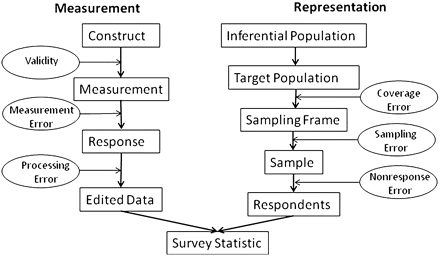
M. Groves, Lars Lyberg, Total Survey Error: Past, Present, and Future, Public Opinion Quarterly, Volume 74, Issue 5, 2010, Pages 849–879, https://doi.org/10.1093/poq/nfq065
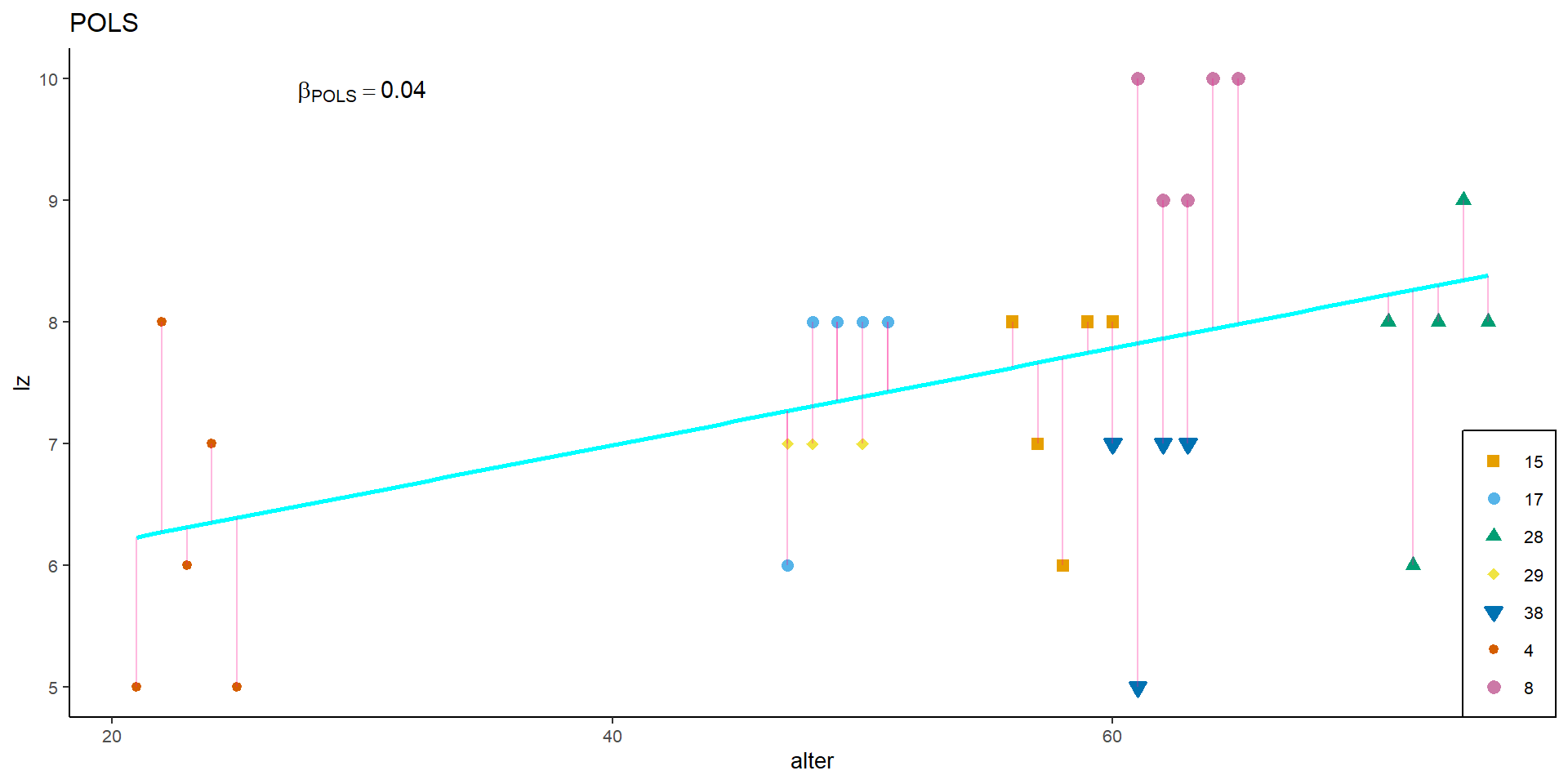
POLS, graphisch
# The palette with black:
cbp2 <- c("#000000",
"#E69F00",
"#56B4E9",
"#009E73",
"#F0E442",
"#0072B2",
"#D55E00",
"#CC79A7")
# Save the residual values
df$predicted <- predict(m_pols)
df$residuals <- residuals(m_pols)
p_pols <- ggplot(df, aes(alter, lz)) +
geom_point( aes(x = alter, y = lz, shape = id_name, colour = id_name, fill = id_name),
size = 2, stroke = 1) +
geom_smooth(method = 'lm', formula = y ~ x, se = FALSE,
color = "cyan") +
geom_segment(aes(xend = alter, yend = predicted),
alpha = .3, color = "deeppink") +
annotate("text", x = 30, y = 9.9,
label = paste0("beta[POLS] ==", round(m_pols$coefficients[2], 3)),
parse = TRUE) +
scale_colour_manual(values = cbp2[-c(1)]) +
scale_fill_manual(values = cbp2[-c(1)]) +
scale_shape_manual(values = c(15:18, 25, 20, 21)) +
ggtitle("POLS") +
theme_classic() +
theme(legend.key = element_blank(),
legend.title = element_blank(),
text = element_text(size = 10),
legend.position = c(1,0),
legend.justification = c("right", "bottom"),
legend.background = element_blank(),
legend.box.background = element_rect(colour = "black"))
p_pols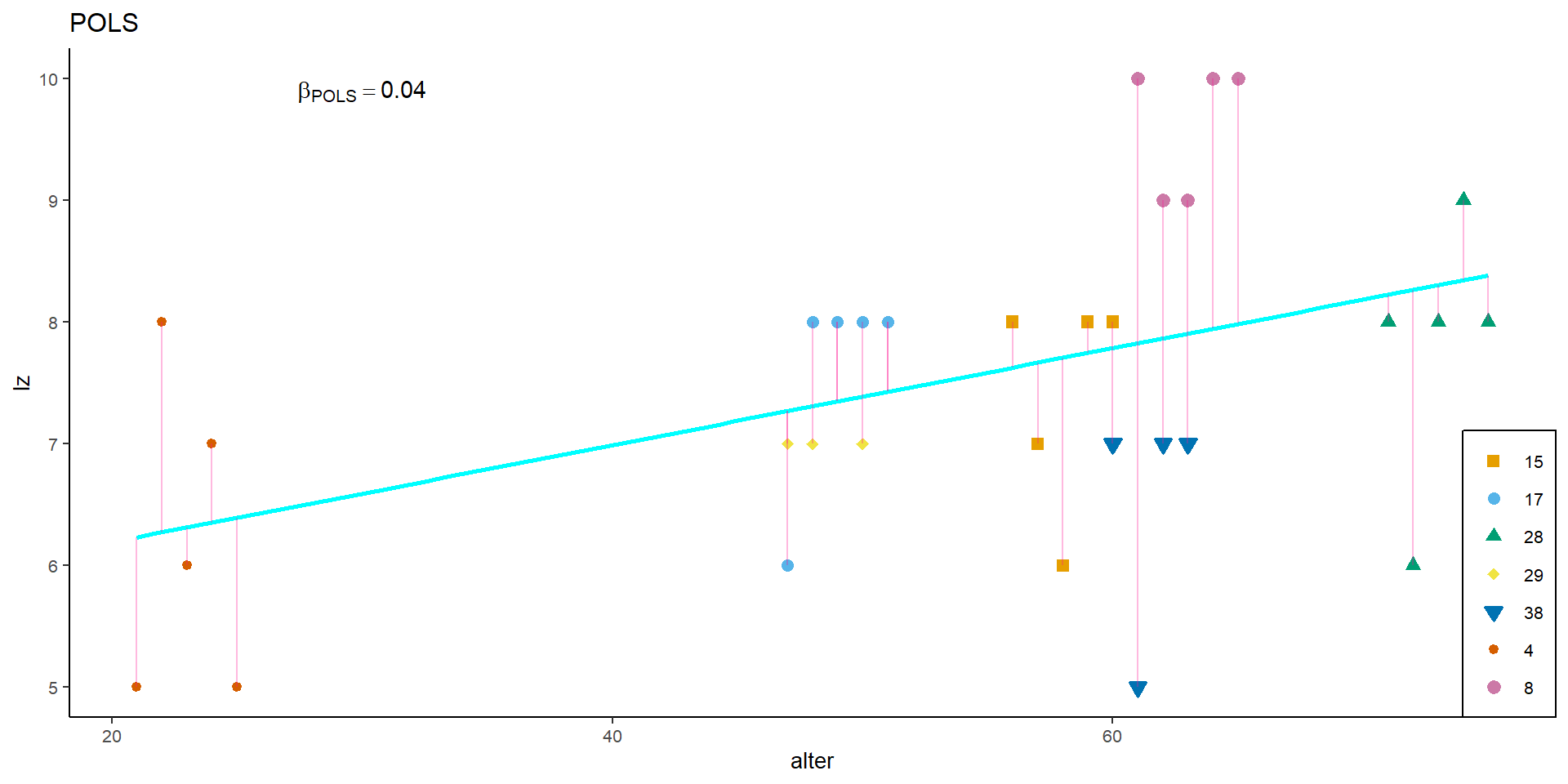
Interpretation: Je höher das Alter einer Person, desto höher ihre Lebenszufriedenheit.
BE, graphisch
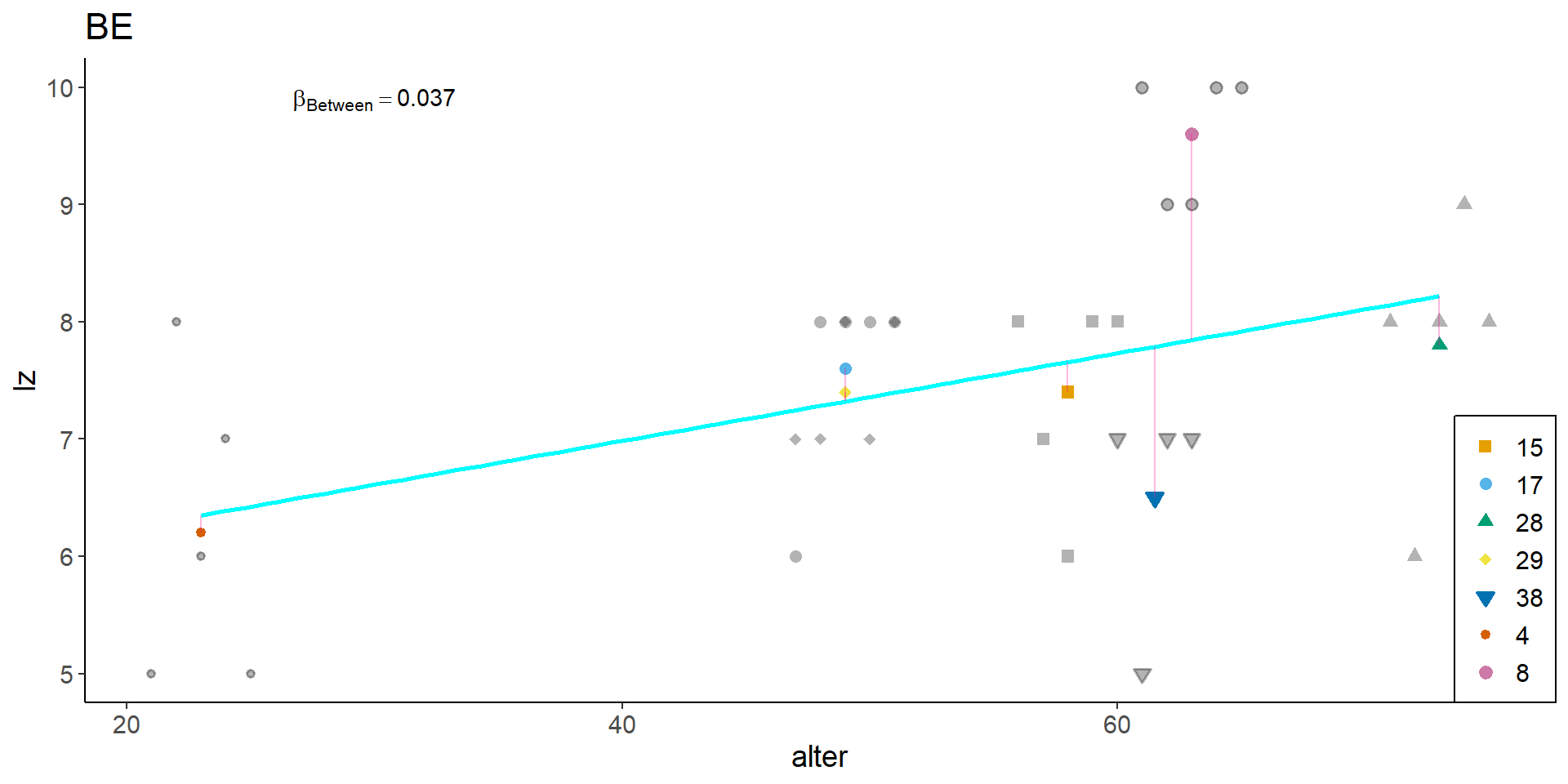
df2 <- df
df2$lz <- df2$m_lz
df2$alter <- df2$m_alter
df2 <- df2[which(df2$syear == 2019), ]
# Save the residual values
m_be <- lm(m_lz ~ m_alter, data = df2)
df2$predicted <- predict(m_be)
df2$residuals <- residuals(m_be)
p_be <- ggplot(df, aes(alter, lz)) +
geom_point(aes(x = alter, y = lz, shape = id_name),
size = 2, stroke = 1, colour = alpha("black", .3), fill = alpha("black", .3)) +
geom_point(aes(x = m_alter, y = m_lz, shape = id_name, colour = id_name,
fill = id_name),
size = 2, stroke = 1) +
geom_smooth(data = df2,
method = 'lm', formula = y ~ x, se = FALSE,
color = "cyan") +
geom_segment(data = df2, aes(xend = alter, yend = predicted),
alpha = .3, color = "deeppink") +
annotate("text", x = 30, y = 9.9,
label = paste0("beta[Between] ==", round(m_be$coefficients[2], 3)),
parse = TRUE) +
scale_colour_manual(values = cbp2[-c(1)]) +
scale_fill_manual(values = cbp2[-c(1)]) +
scale_shape_manual(values = c(15:18, 25, 20, 21)) +
ggtitle("BE") +
theme_classic() +
theme(legend.key = element_blank(),
legend.title = element_blank(),
text = element_text(size = 14),
legend.position = c(1,0),
legend.justification = c("right", "bottom"),
legend.background = element_blank(),
legend.box.background = element_rect(colour = "black"))
p_be 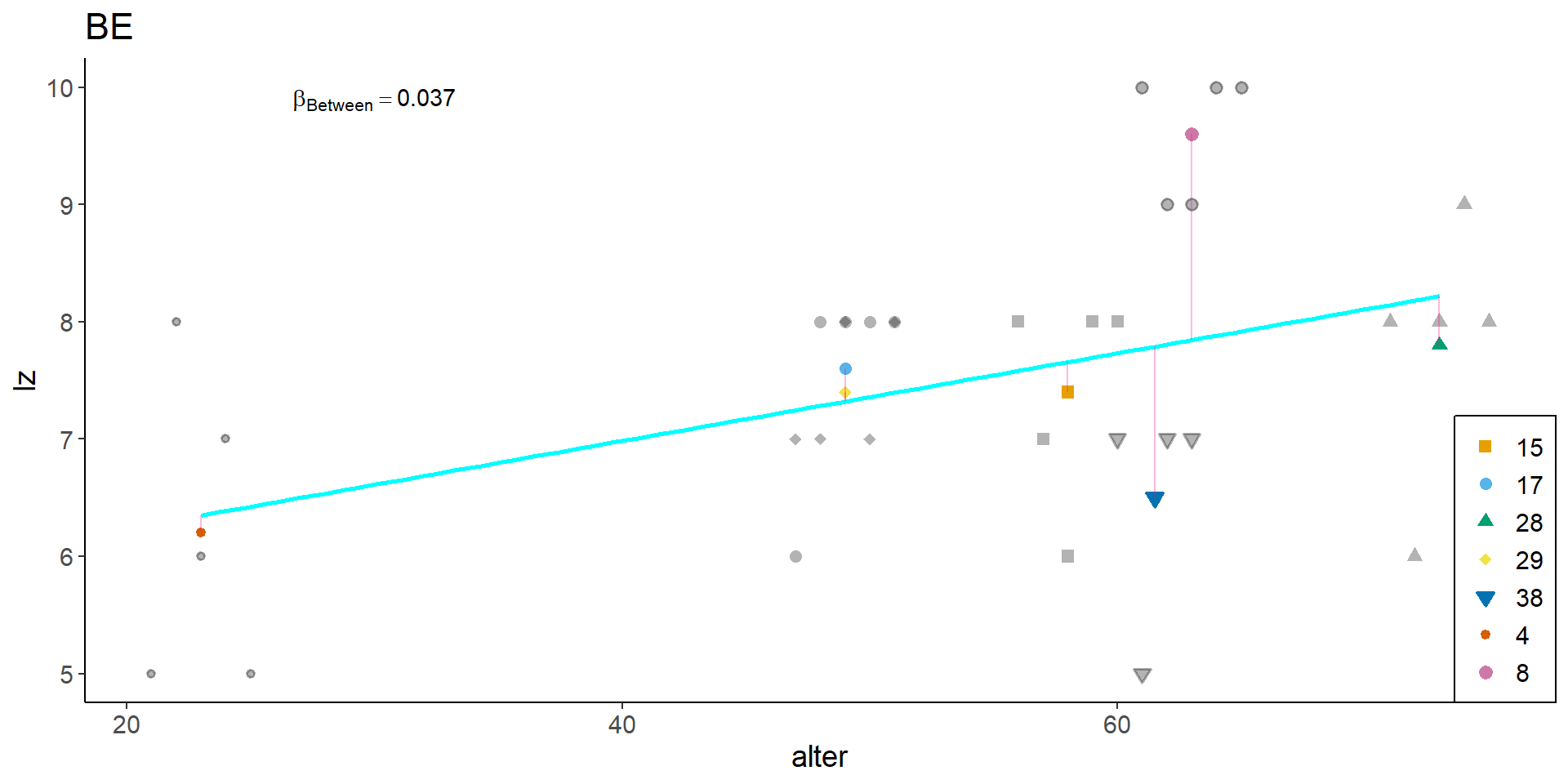
Regressionsmodelle: Within Schätzer
\[ y_{it} - \bar{y}_{i}= \alpha_i-\alpha_i + \beta_1(x_{it}- \bar{x}_i) + \beta_2(z_{i}- \bar{z}_i) + \epsilon_{it}-\bar{\epsilon}_{i} + u_{i}-\bar{u}_{i}, \]
\[ y_{it} - \bar{y}_{i}= \beta_1(x_{it}- \bar{x}_i) + \epsilon_{it}-\bar{\epsilon}_{i}, \]
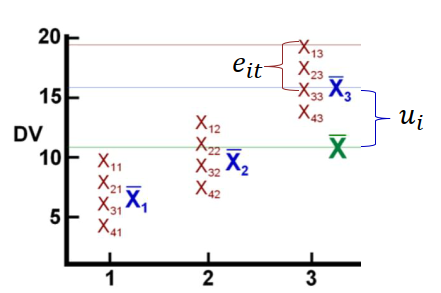
Within, graphisch
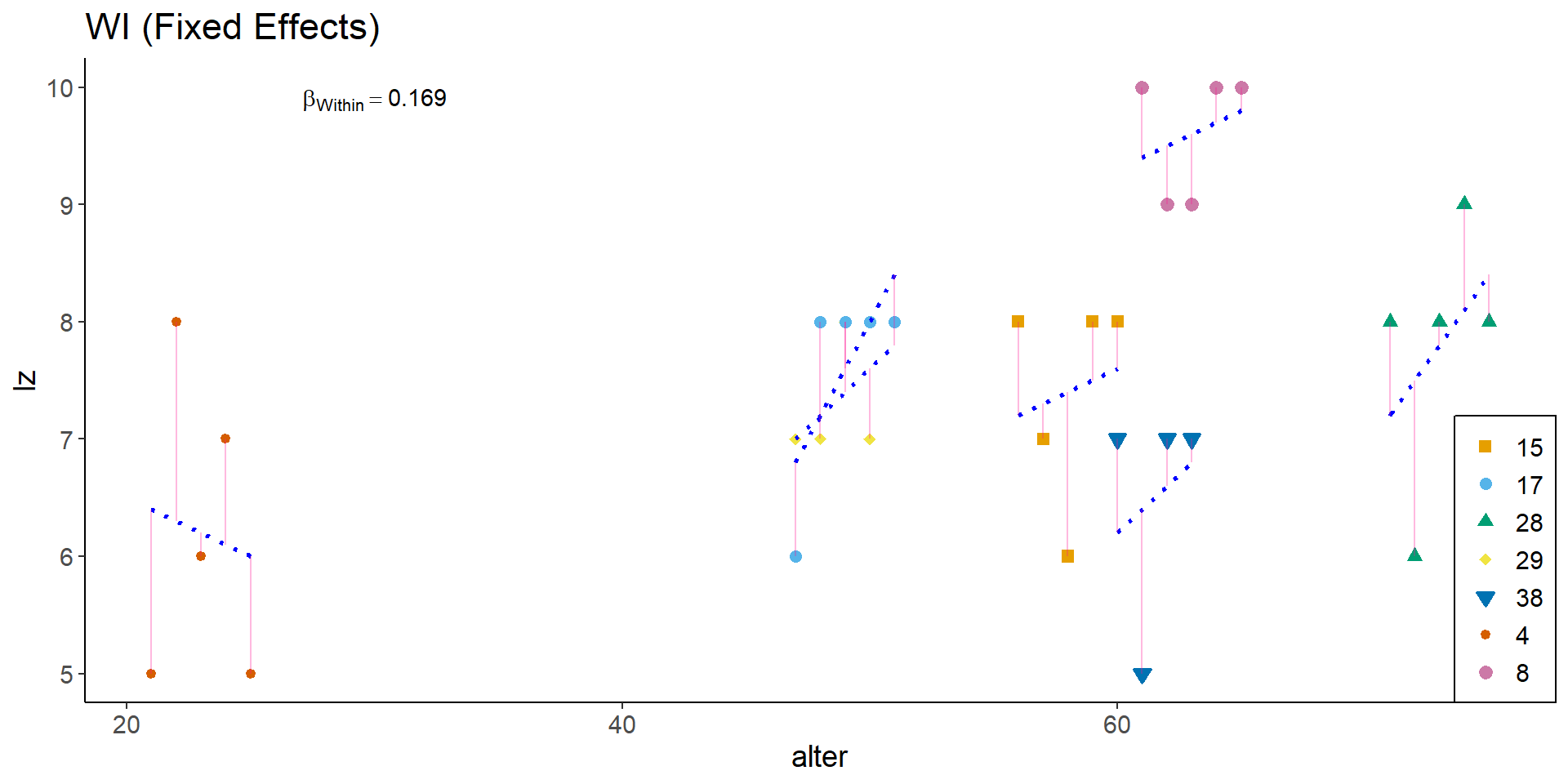
# Lineares regressionsmodell für jede Person i
# und Residuen speichern
for(i in unique(df$id)){
oo <- which(df$id == i)
lmt <- lm(lz ~ alter, data = df[oo, ])
df$predicted[oo] <- predict(lmt)
df$residuals[oo] <- residuals(lmt)
}
g_wi <- ggplot(df, aes(alter, lz)) +
geom_point( aes(x = alter, y = lz, shape = id_name, colour = id_name, fill = id_name),
size = 2, stroke = 1) +
geom_smooth(method = 'lm', formula = y ~ x, se = FALSE, show.legend = FALSE,
mapping = aes(group = id_name),
color = "blue", linetype = "dotted") +
geom_segment(data = df, aes(xend = alter, yend = predicted),
alpha = .3, color = "deeppink") +
annotate("text", x = 30, y = 9.9,
label = paste0("beta[Within] ==", round(m_fe$coefficients[2], 3)),
parse = TRUE) +
scale_fill_manual(values = cbp2[-c(1)]) +
scale_colour_manual(values = cbp2[-c(1)]) +
scale_shape_manual(values = c(15:18, 25, 20, 21)) +
ggtitle("WI (Fixed Effects)") +
theme_classic() +
theme(legend.key = element_blank(),
legend.title = element_blank(),
text = element_text(size = 14),
legend.position = c(1,0),
legend.justification = c("right", "bottom"),
legend.background = element_blank(),
legend.box.background = element_rect(colour = "black"))
g_wi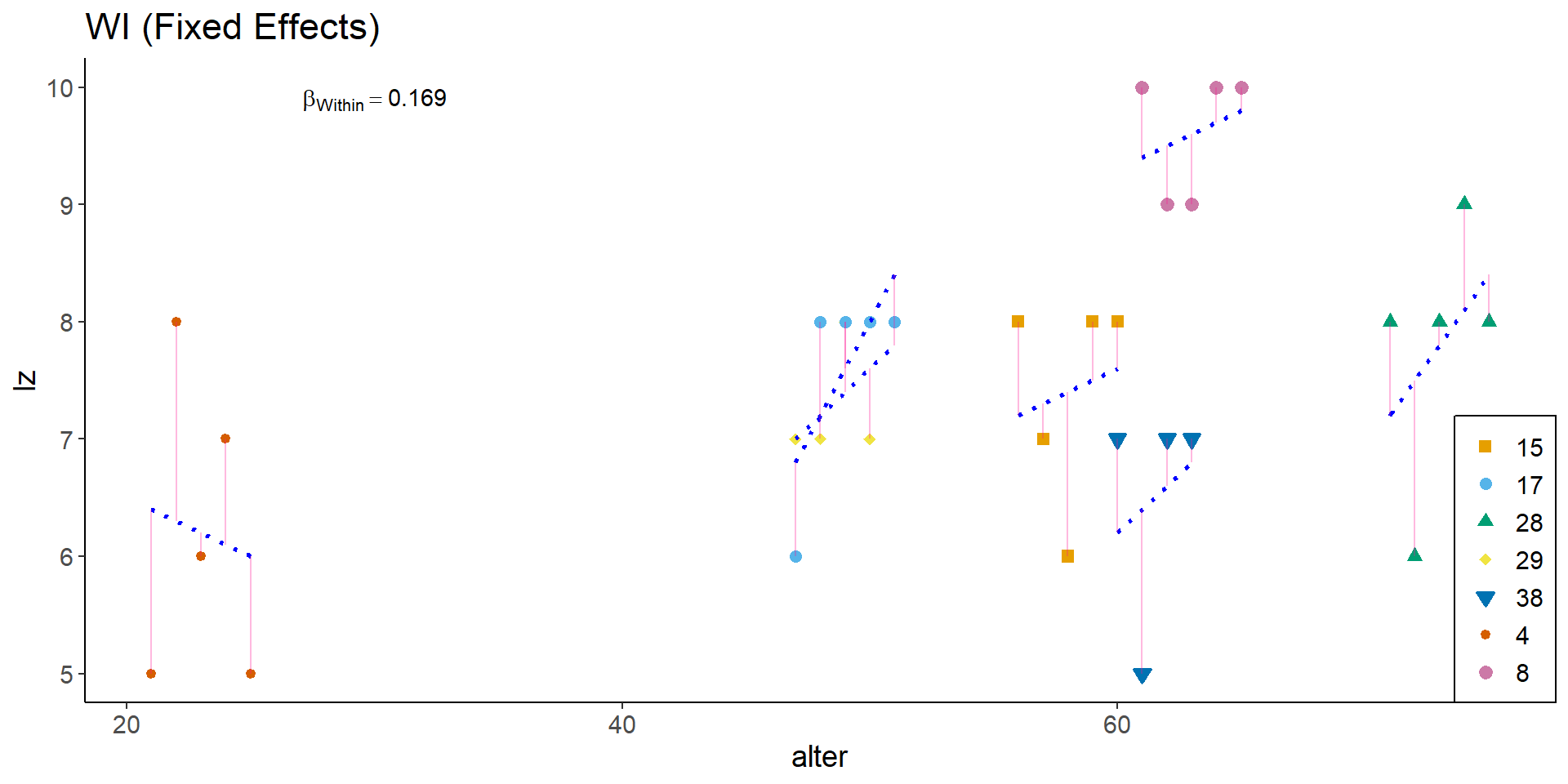
DAGs
Direct acyclic graph (DAG): eine grafische Darstellung der kausalen Annahmen in dem Datengenerierungsprozess
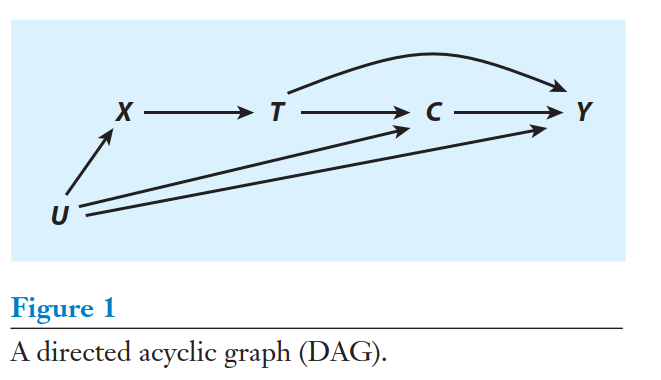
Elwert & Winship (2014)
Overcontrol bias
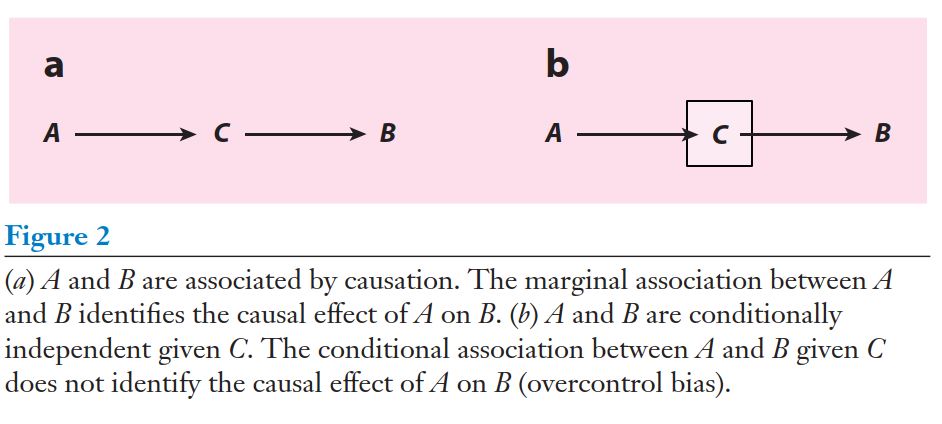
Elwert & Winship (2014)
Confounding
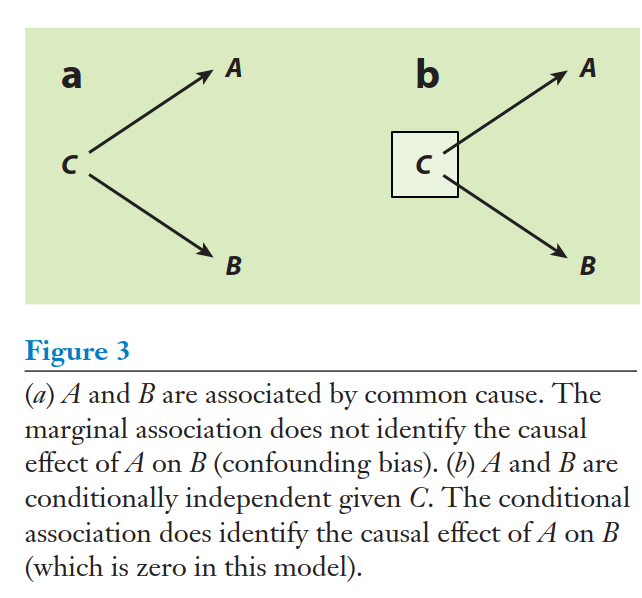
Elwert & Winship (2014)
Endogenous selection bias
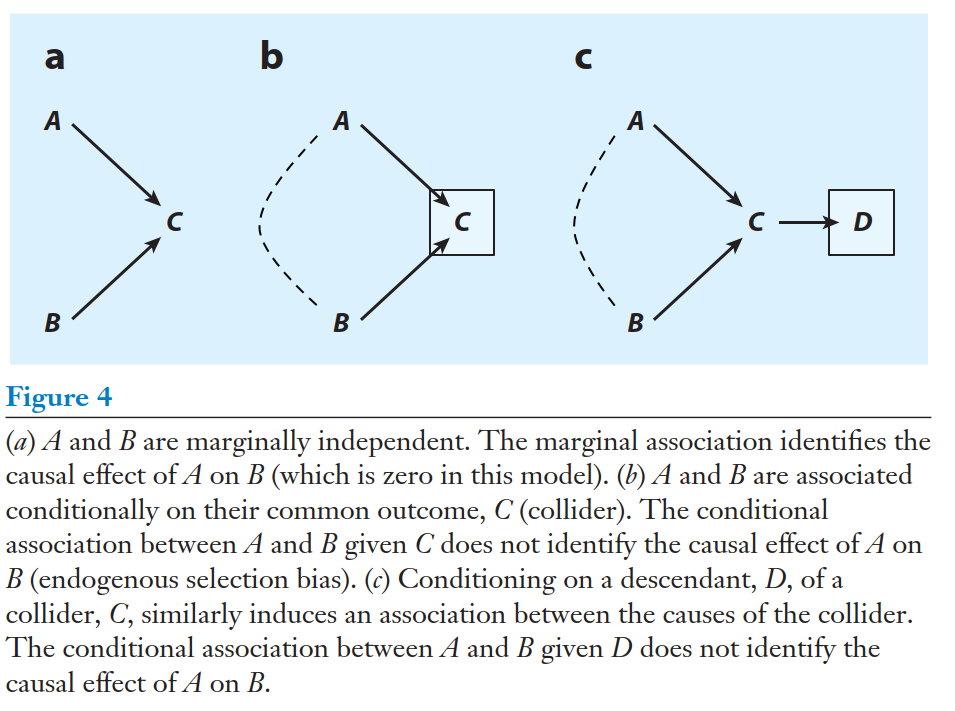
Elwert & Winship (2014)