1. Seminar
Fortgeschrittene quantitative Methoden
Wintersemester 2024-2025
Datenvisualisierung
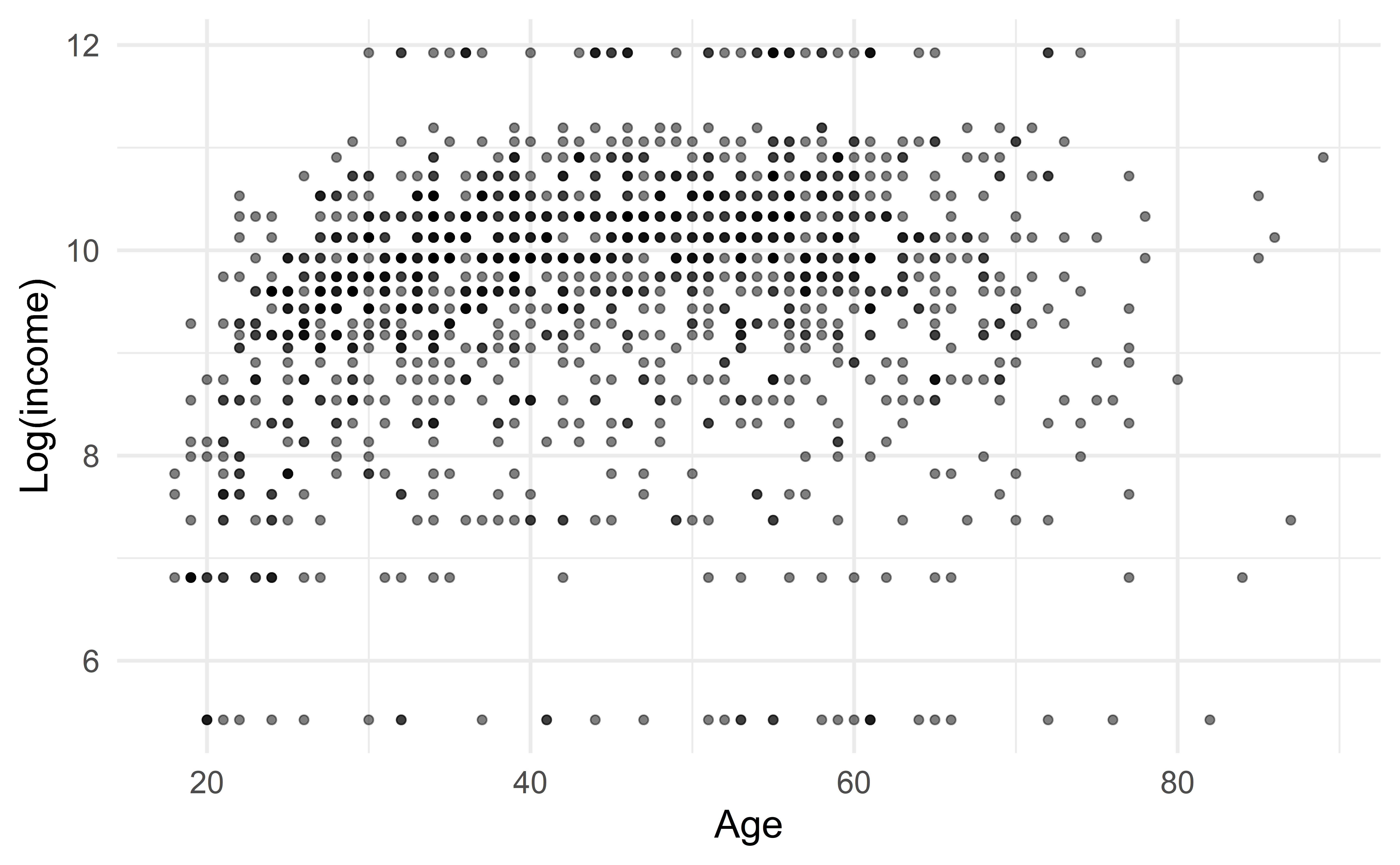
Fit a line
… um die Beziehung zwischen Alter und Einkommen zu beschreiben
p <- ggplot(data = df,
mapping = aes(x = age, y = log(realrinc))) +
geom_point(alpha = 0.5) +
geom_smooth(method = "lm", color = "purple", se = FALSE) +
labs(
x = "Age" ,
y = "Log(income)"
)
p`geom_smooth()` using formula = 'y ~ x'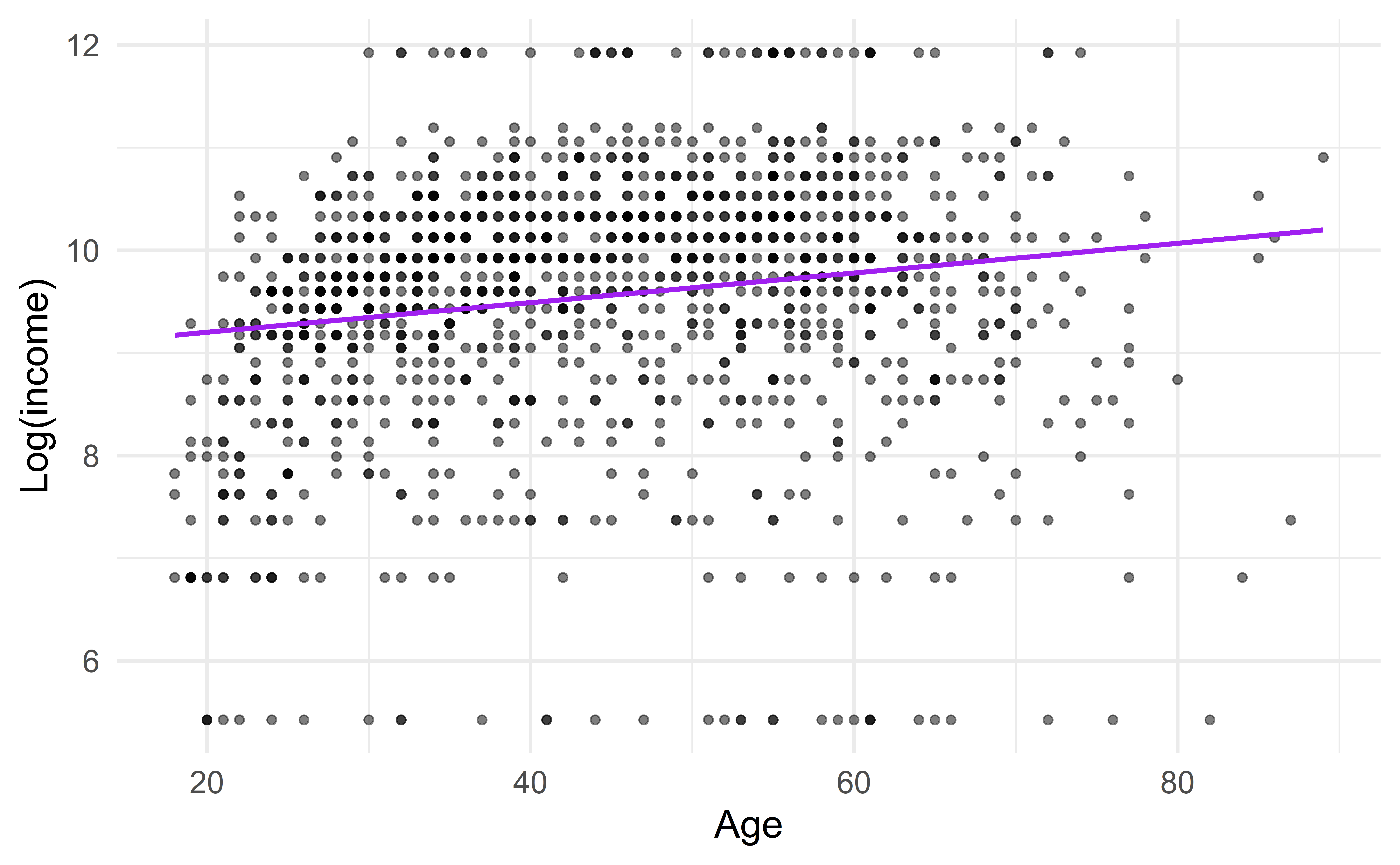
Terminologie
Regressionsmodel
\[ \begin{aligned} Y &= \color{purple}{\textbf{Model}} + \text{Error} \\[8pt] &= \color{purple}{\mathbf{f(X)}} + \epsilon \\[8pt] &= \color{purple}{\boldsymbol{\mu_{Y|X}}} + \epsilon \end{aligned} \]
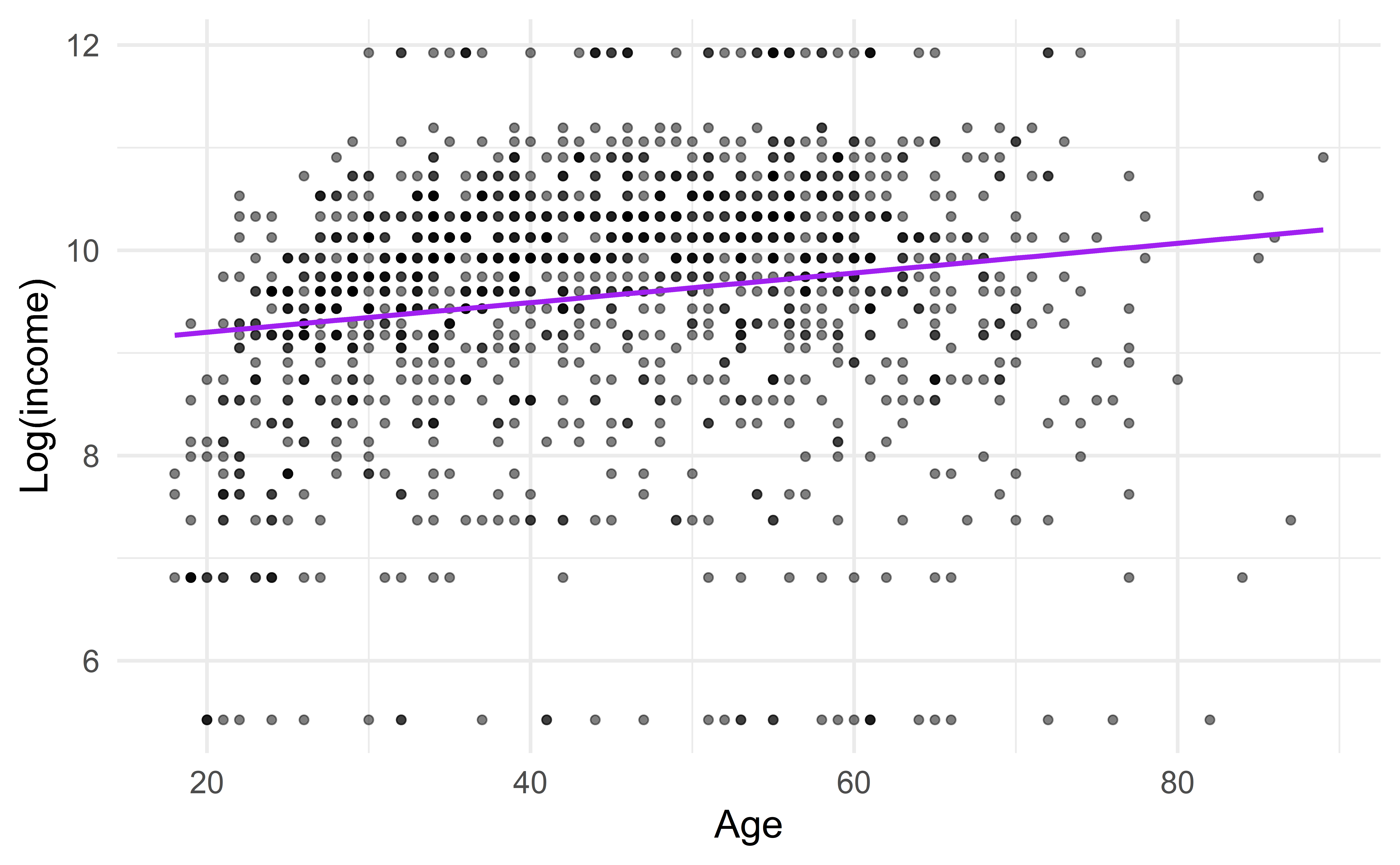
m <- lm(log(realrinc) ~ age, data = df)
df$predicted <- predict(m)
ggplot(data = df,
mapping = aes(x = age, y = log(realrinc))) +
geom_point(alpha = 0.5) +
geom_smooth(method = "lm", color = "purple", se = FALSE) +
labs(x = "X", y = "Y") +
theme_minimal() +
theme(
axis.text = element_blank(),
axis.ticks.x = element_blank(),
axis.ticks.y = element_blank()
)`geom_smooth()` using formula = 'y ~ x'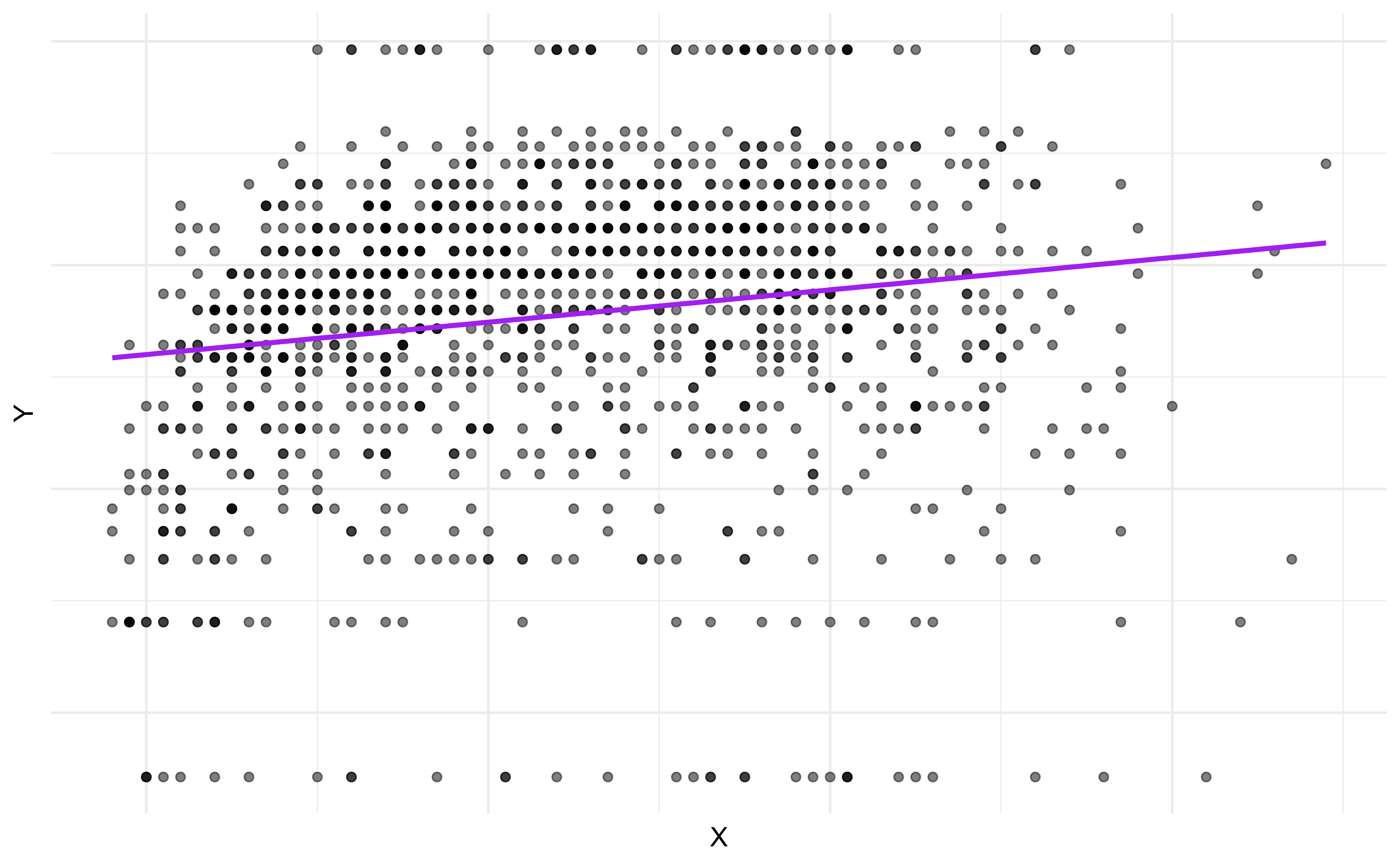
Regressionsmodel + Residuen
\[\begin{aligned} Y &= \color{purple}{\textbf{Model}} + \color{blue}{\textbf{Error}} \\[8pt] &= \color{purple}{\mathbf{f(X)}} + \color{blue}{\boldsymbol{\epsilon}} \\[8pt] &= \color{purple}{\boldsymbol{\mu_{Y|X}}} + \color{blue}{\boldsymbol{\epsilon}} \\[8pt] \end{aligned}\]
`geom_smooth()` using formula = 'y ~ x'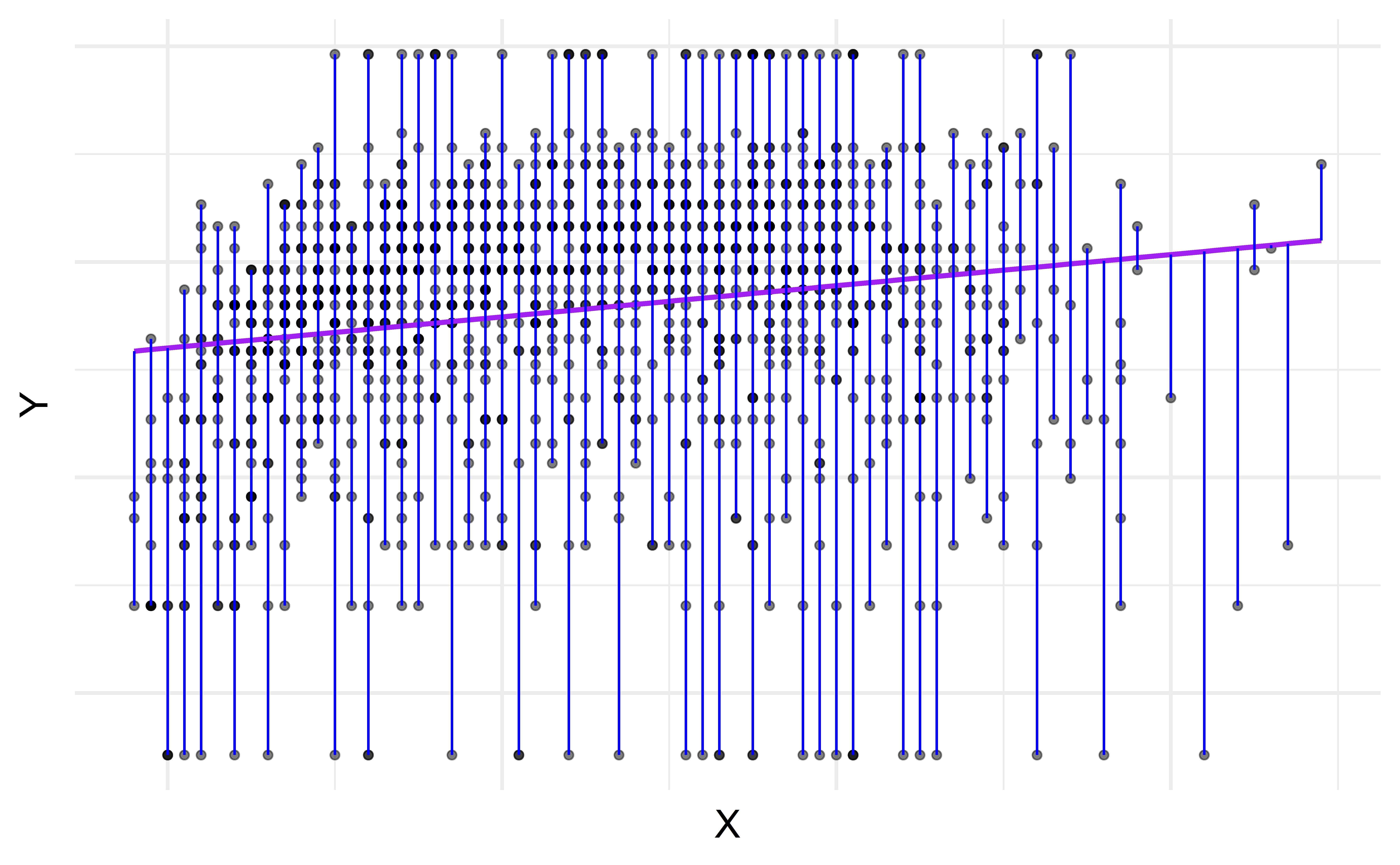
Residuen
ggplot(data = df, mapping = aes(x = age, y = log(realrinc))) +
geom_point(alpha = 0.5) +
geom_smooth(method = "lm", color = "purple", se = FALSE) +
geom_segment(aes(x = age, xend = age, y = log(realrinc), yend = predict(m)), color = "steel blue") +
labs(x = "Alter", y = "Einkommen") +
theme(legend.position = "none")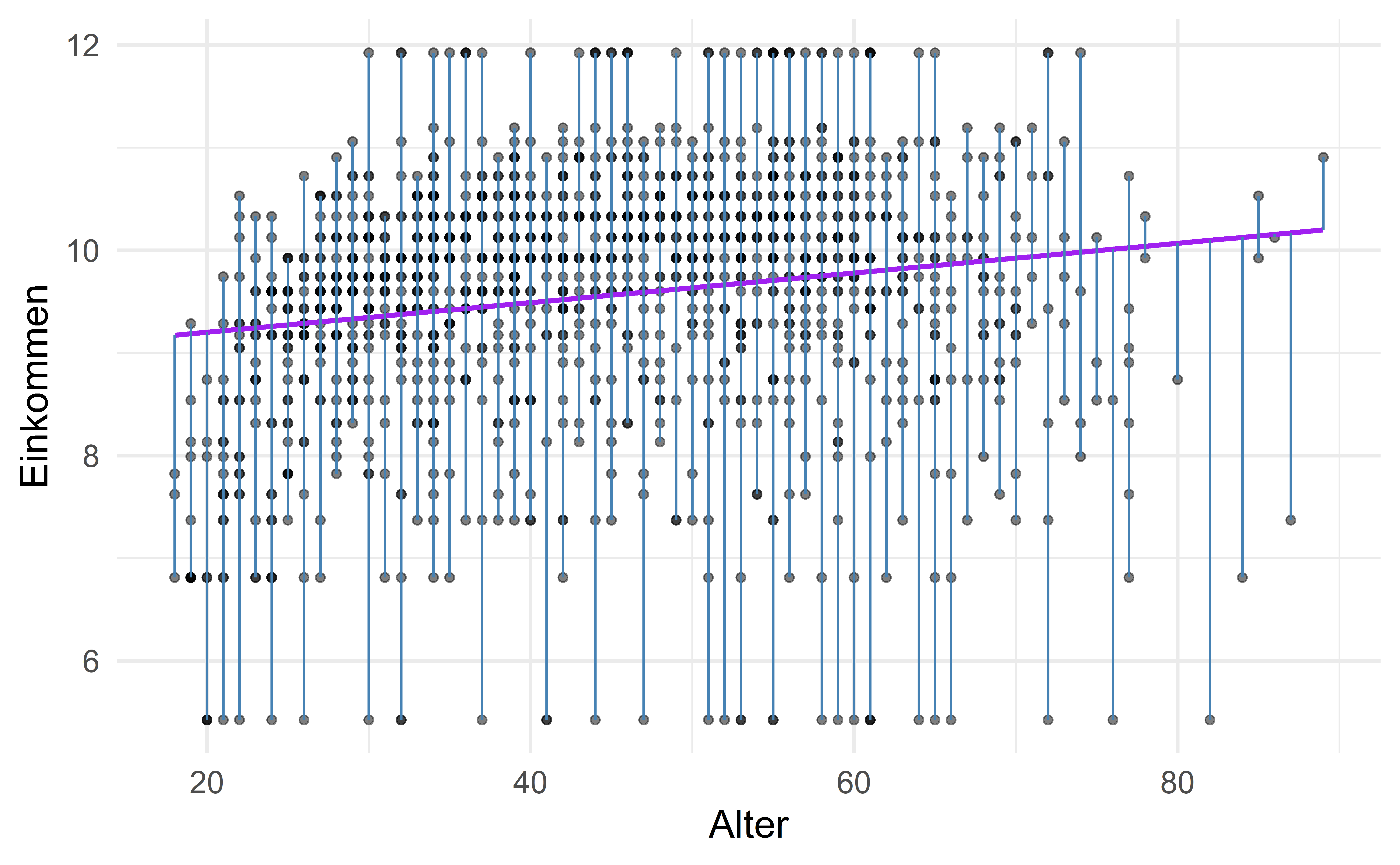
ggplot(data = df, mapping = aes(x = age, y = log(realrinc))) +
geom_point(alpha = 0.5) +
geom_smooth(method = "lm", color = "purple", se = FALSE) +
geom_segment(aes(x = age, xend = age, y = log(realrinc), yend = predict(m)), color = "steel blue") +
labs(x = "Alter", y = "Einkommen") +
theme(legend.position = "none")`geom_smooth()` using formula = 'y ~ x'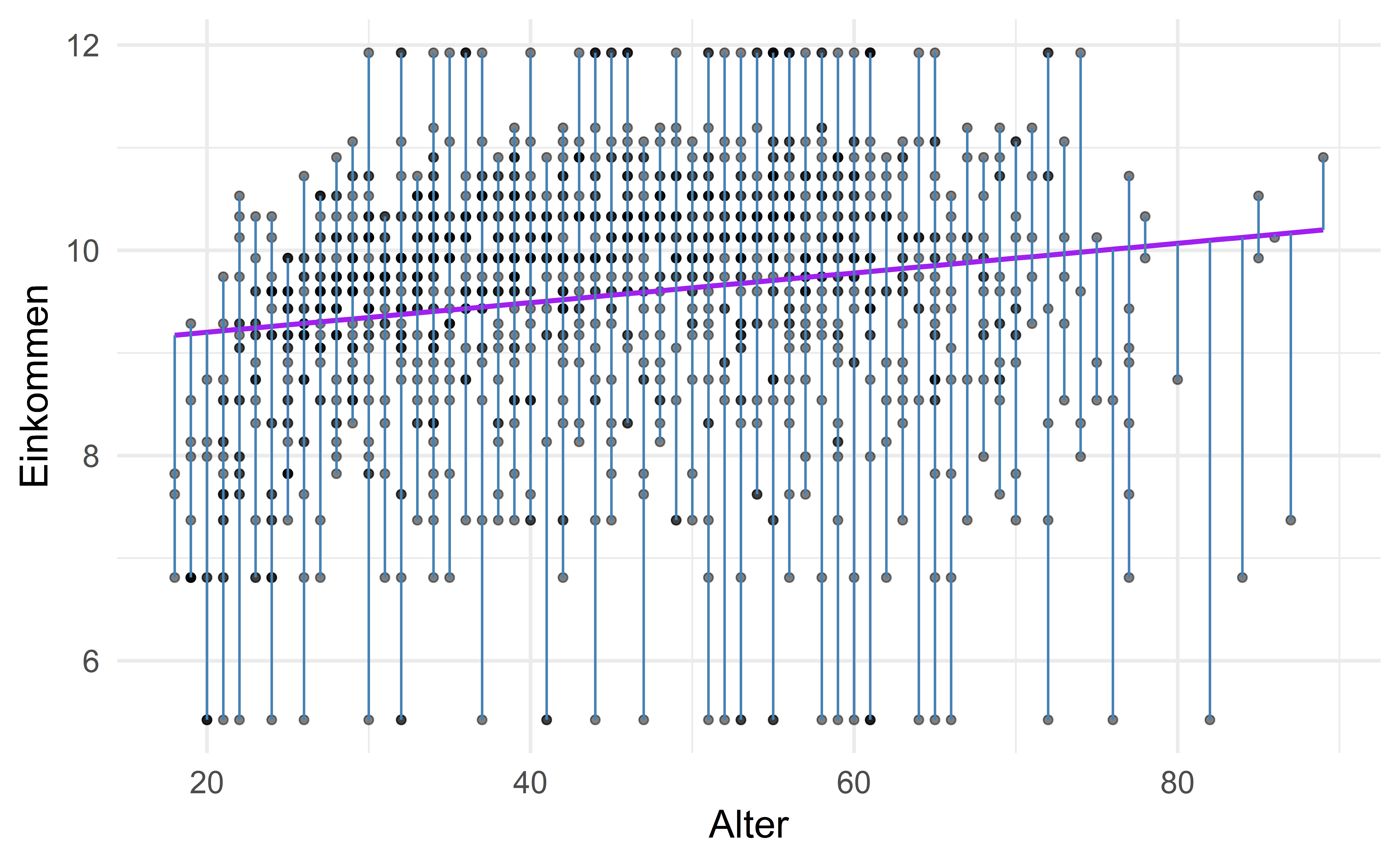
\[\text{Residuen} = \text{Beobachted} - \text{Vorhergesagt} = y - \hat{y}\]