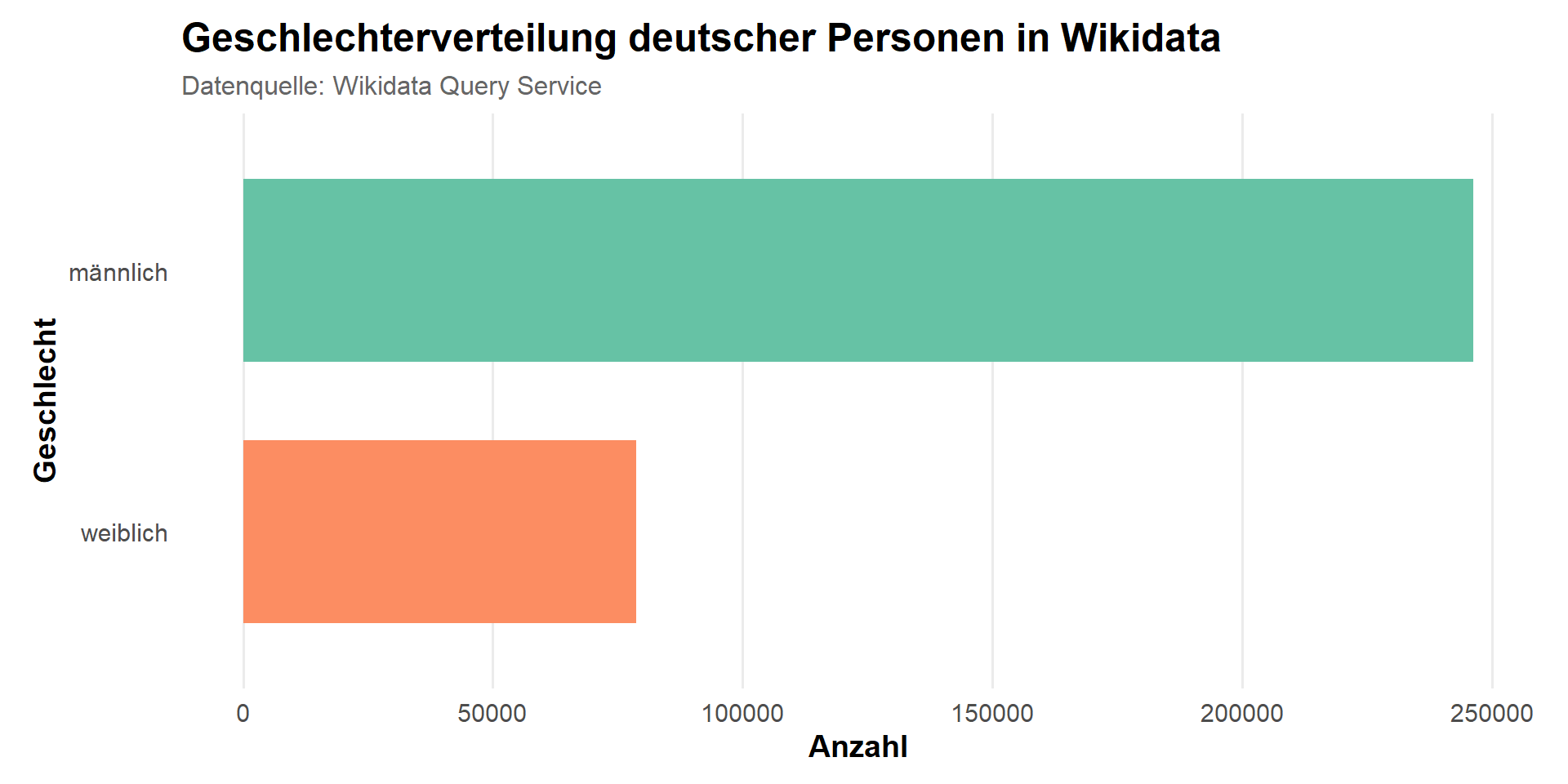
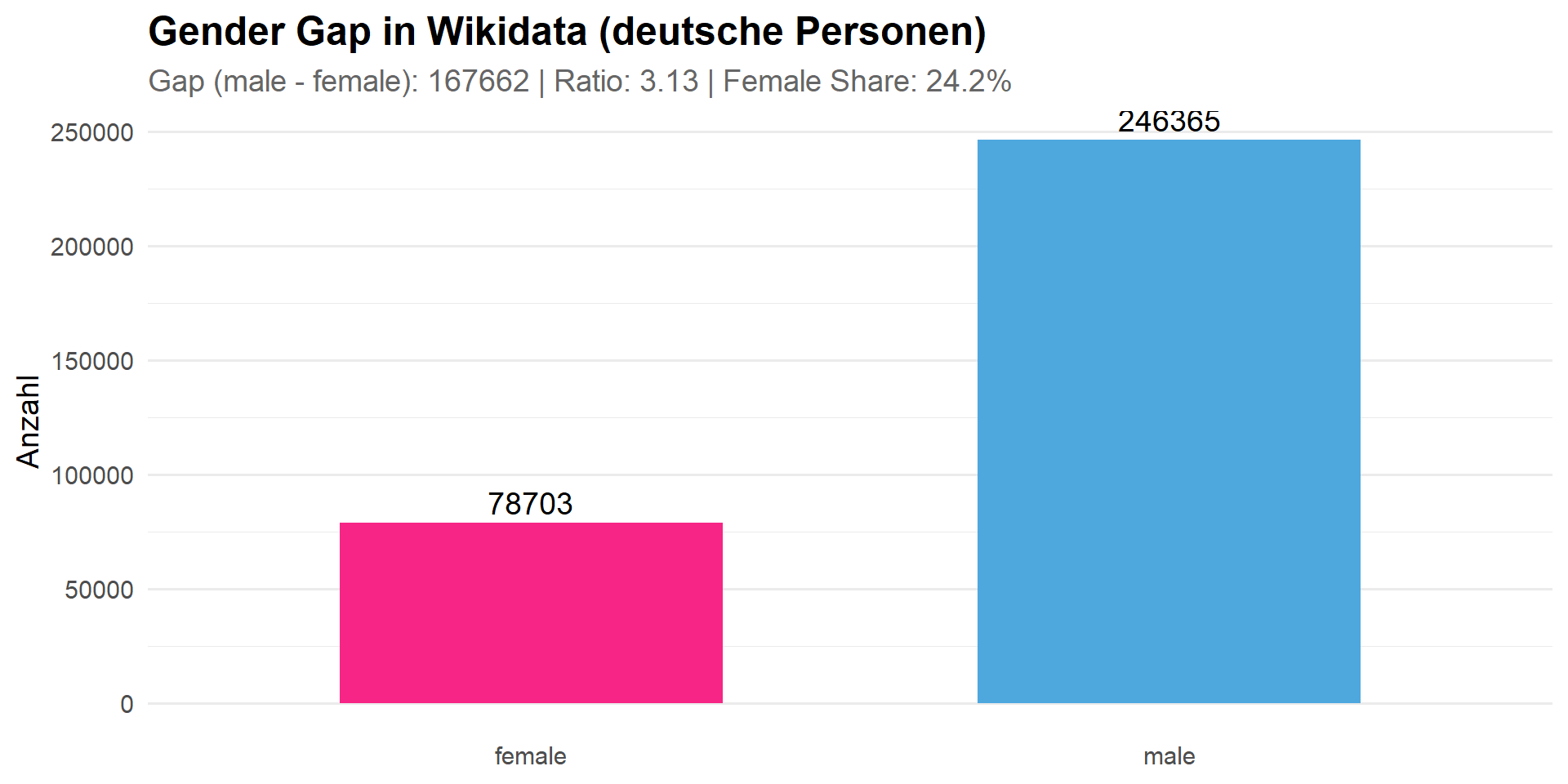
Gender Aspekte der Data Science
Sitzung 2b: Themensuche | Daten extrahieren | Forschungsdatenmanagement
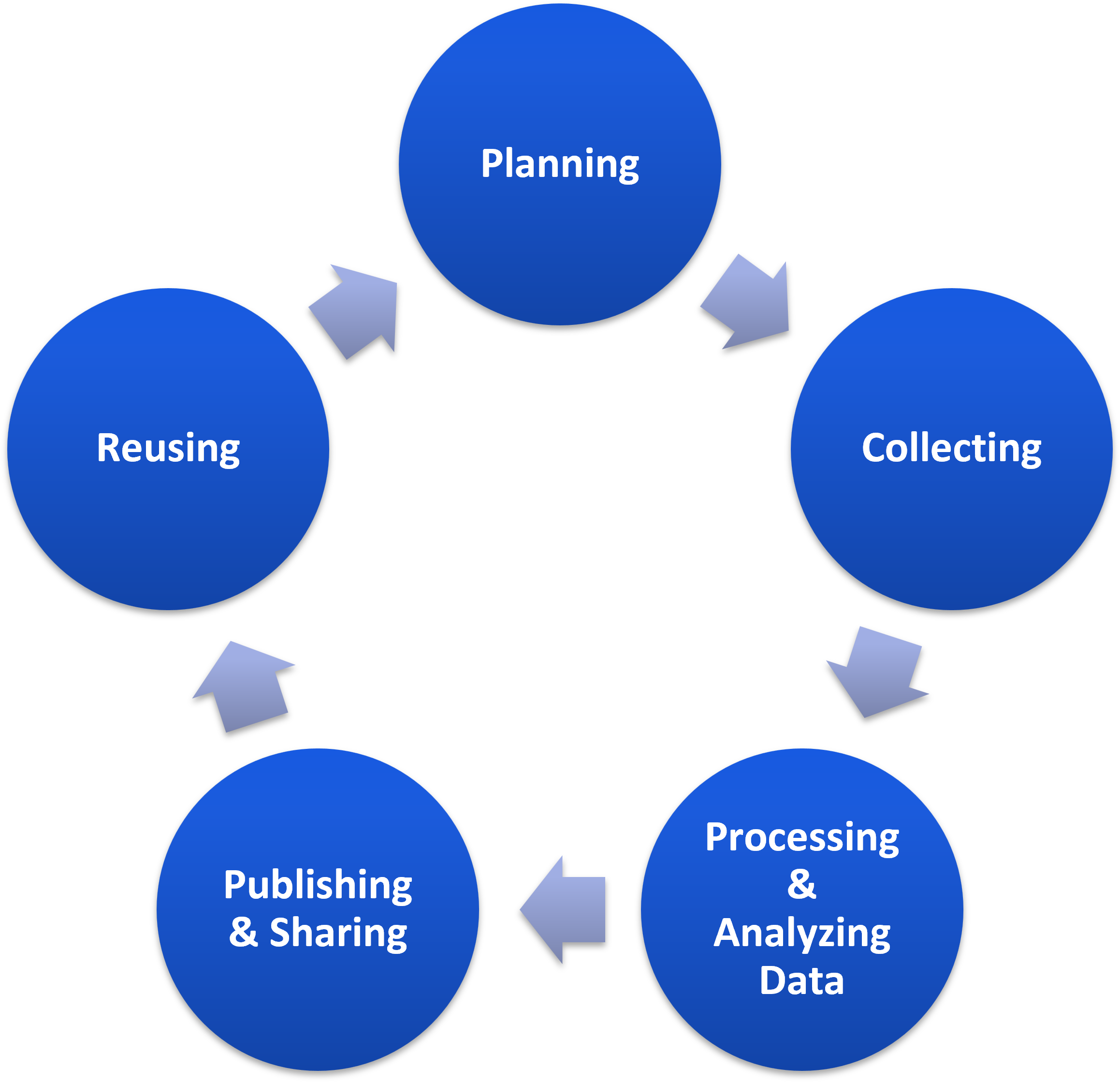
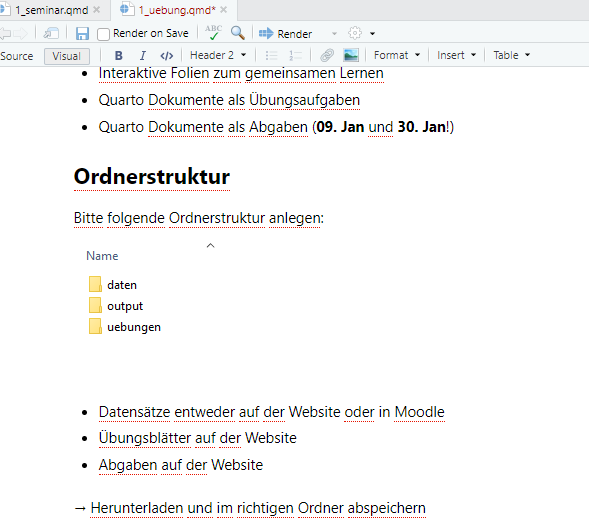
Übersicht: Forschungsdatenmanagement
Was ist Quarto?
ist ein neues, quelloffenes, wissenschaftliches und technisches Publikationssystem
Das Ziel von Quarto ist es, den Prozess der Erstellung und Zusammenarbeit an wissenschaftlichen und technischen Dokumenten deutlich zu verbessern
![]()

YAML
Dokument metadata

YAML ausführlicher
Dokument metadata

Text
Markdown kann mit jedem Editor bearbeitet werden, auch mit den Quelltext- oder visuellen Editoren von RStudio.
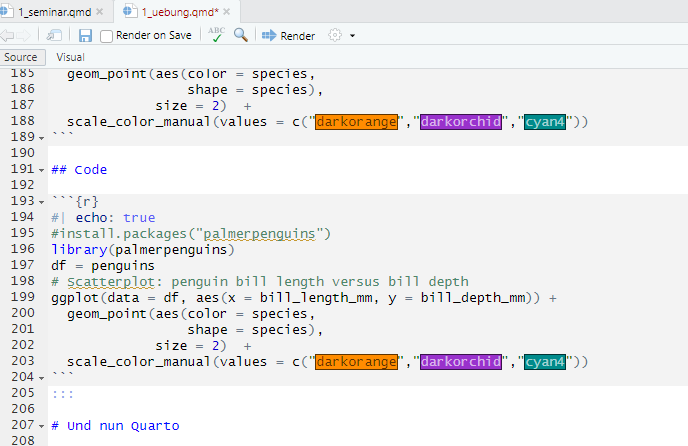
Code
Code kann auch mit den Quelltext- oder visuellen Editoren von RStudio bearbeitet werden
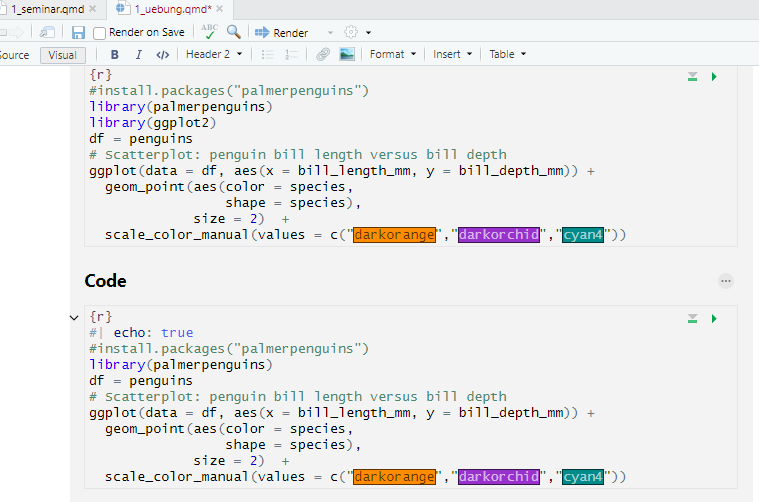
Datenvisualisierung